浏览器基础
主要根据keenan师傅的博客进行学习
web浏览器结构
现代浏览器的结构基本如下(参考web-browser-architecture)
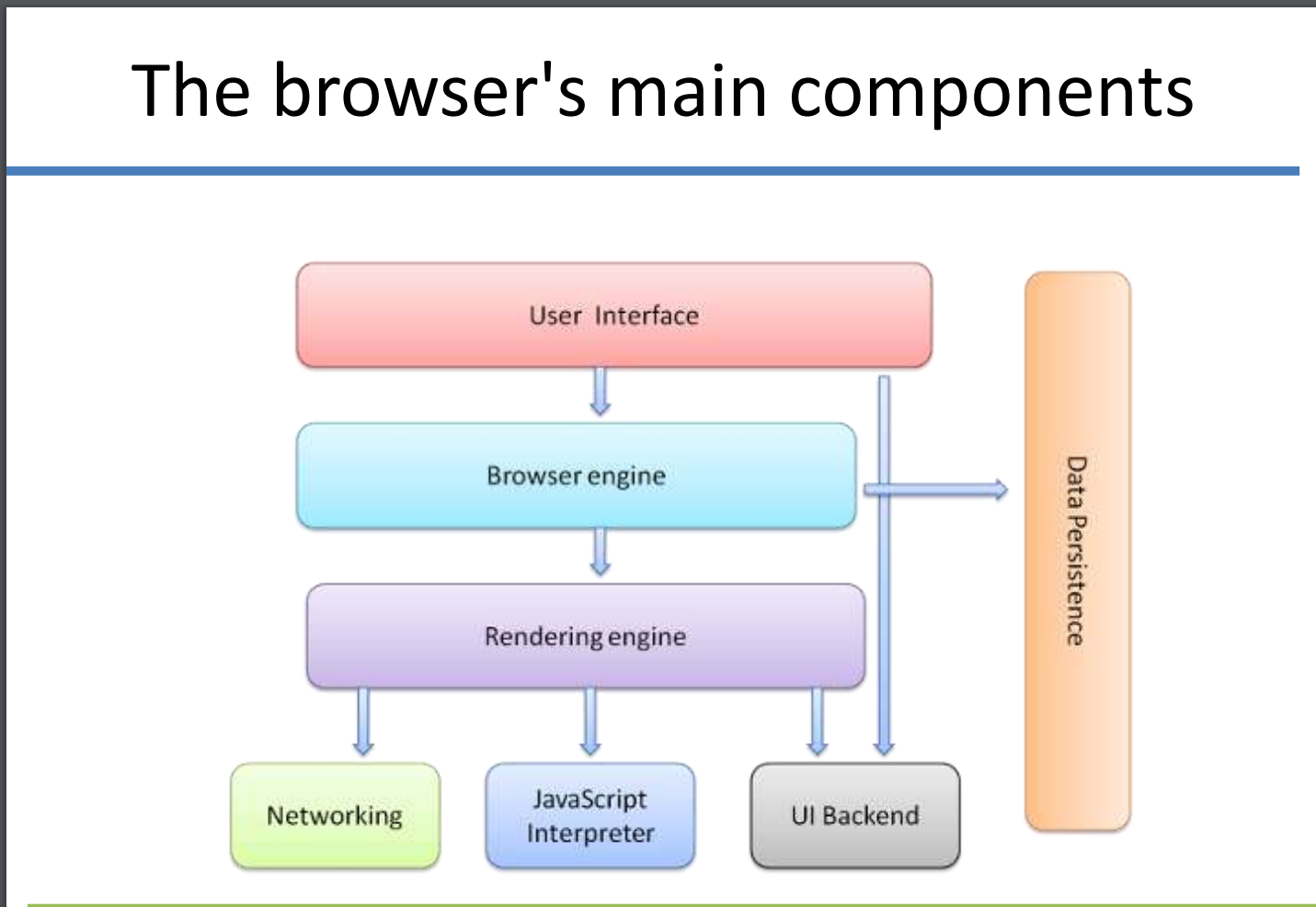
- The User Interface(用户接口):提供用户和浏览器引擎的交互方法,比如地址栏,前进、后退按钮,书签等。除了你看到的请求页面外,浏览器前端展示出的部分都属于它
- The Browser Engine(浏览器引擎):封装UI和渲染引擎的操作。它为渲染引擎提供顶层接口。浏览器引擎提供方法来加载一个URL和其他顶层的浏览器动作(reload/back/forward)。浏览器引擎还提供给用户许多同错误信息和加载进程相关的信息。
- The Rendering Engine(渲染引擎):它生成指定URL的可视化表示。渲染引擎解释包含指定URL的HTML,XML以及Javascript。其中的一个核心组件是HTML解析器,它很复杂因为它允许渲染引擎展示出一个简陋的HTML页面。不同的浏览器使用不同的渲染引擎。

- The Networking(网络组件):提供方法使用通用的互联网协议如HTTP和FTP处理检索URL。网络组件处理所有方面的网络通信和安全,字符集翻译和MIME类型解析。网络组件为了最小化网络流量可能会实现一个cache保存检索过的文档。
- The JavaScript Interpreter(JS解释器):执行web页面上嵌入的js代码。执行结果被传回到渲染引擎进行展示。渲染引擎或许会禁用许多包含用户定义属性的动作。
- The UI Backend(UI后端):用于绘出基本的小部件,如组合框和窗口;在底层它使用操作系统用户接口方法。
- The Data Storage(数据存储):管理用户数据比如书签,cookie,设置偏好等。HTML5定义了web database,它是浏览器中的一个完整数据库。
常见浏览器的结构
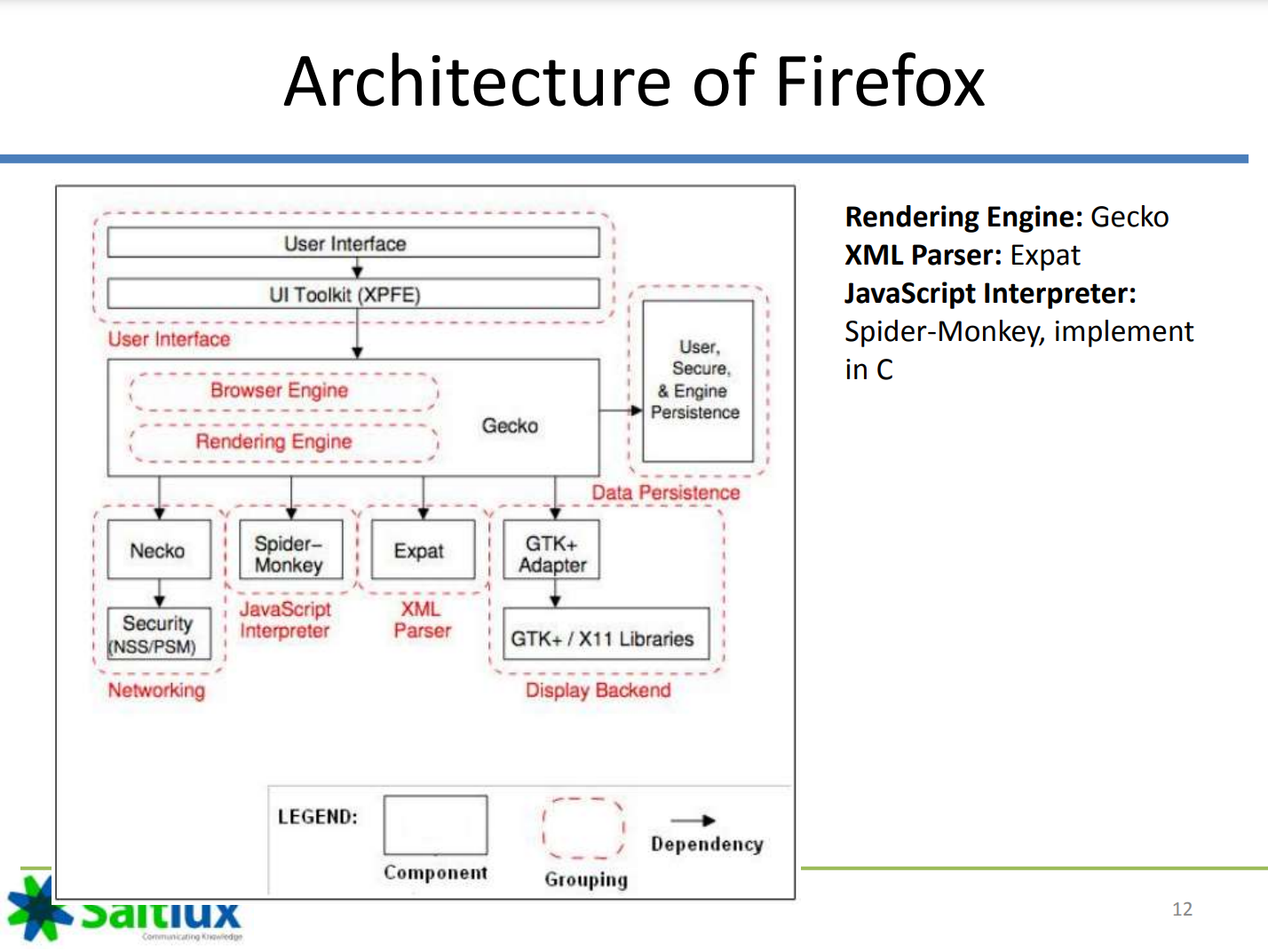
firefox:
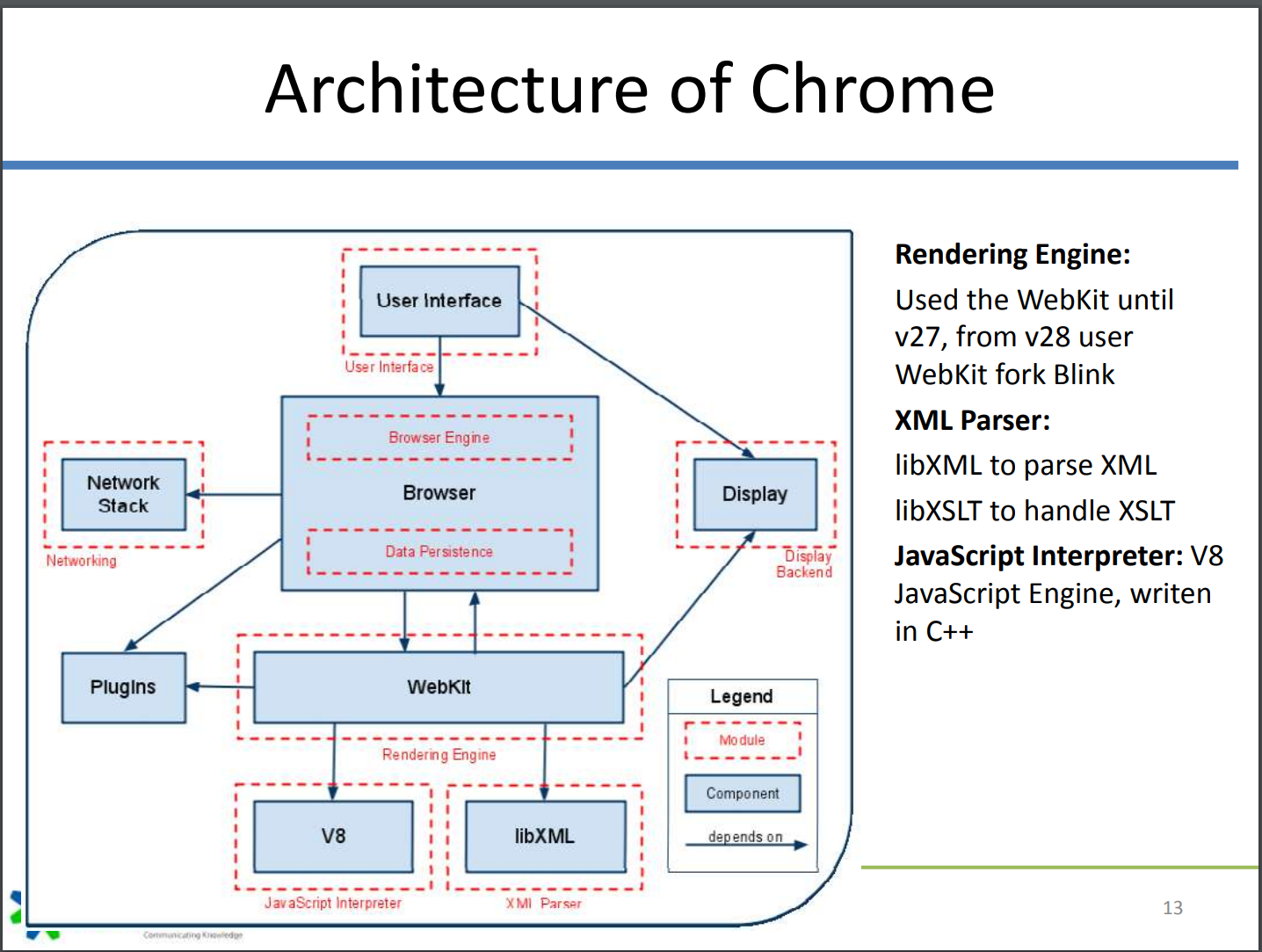
chrome:
这里的Webkit应该是Blink和V8
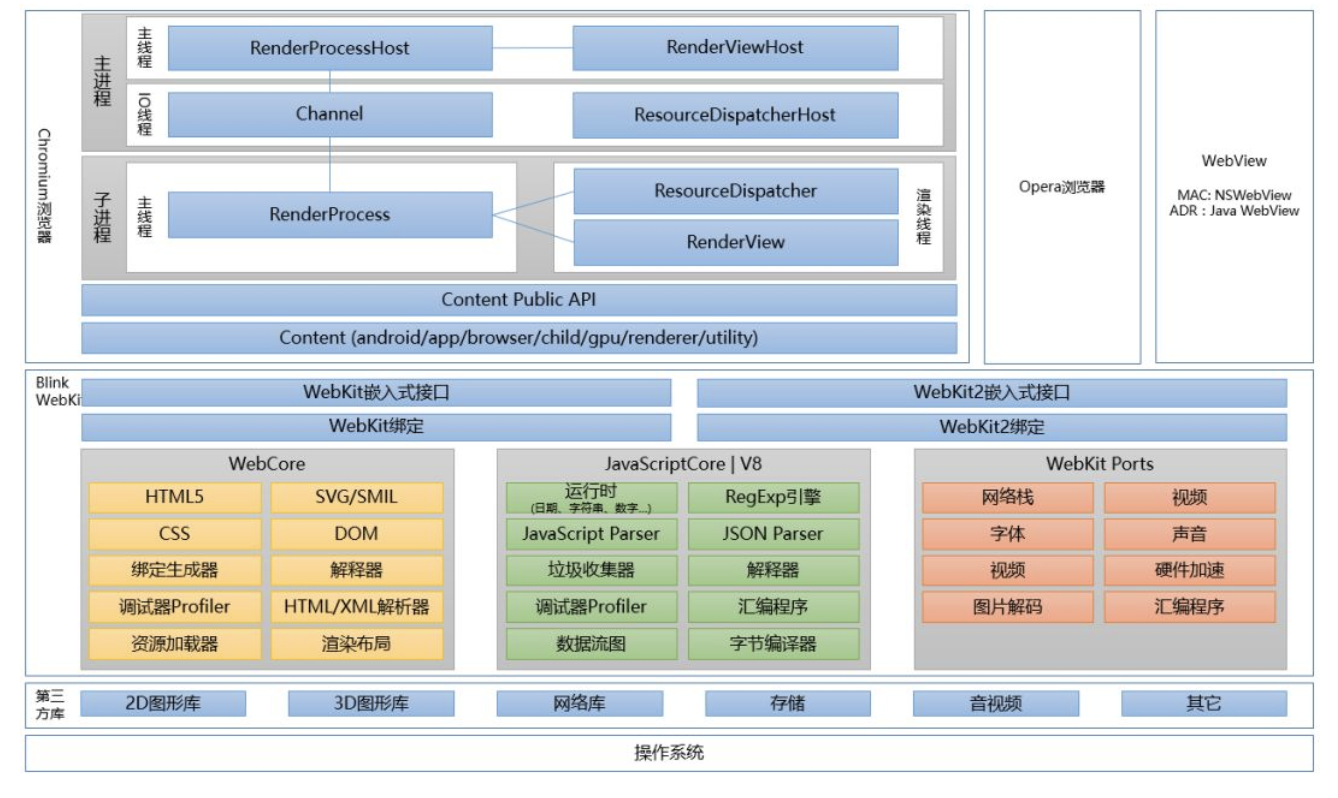
看keenan师傅的博客找到了一张更为详细的图,关于组件如何工作可以看这里
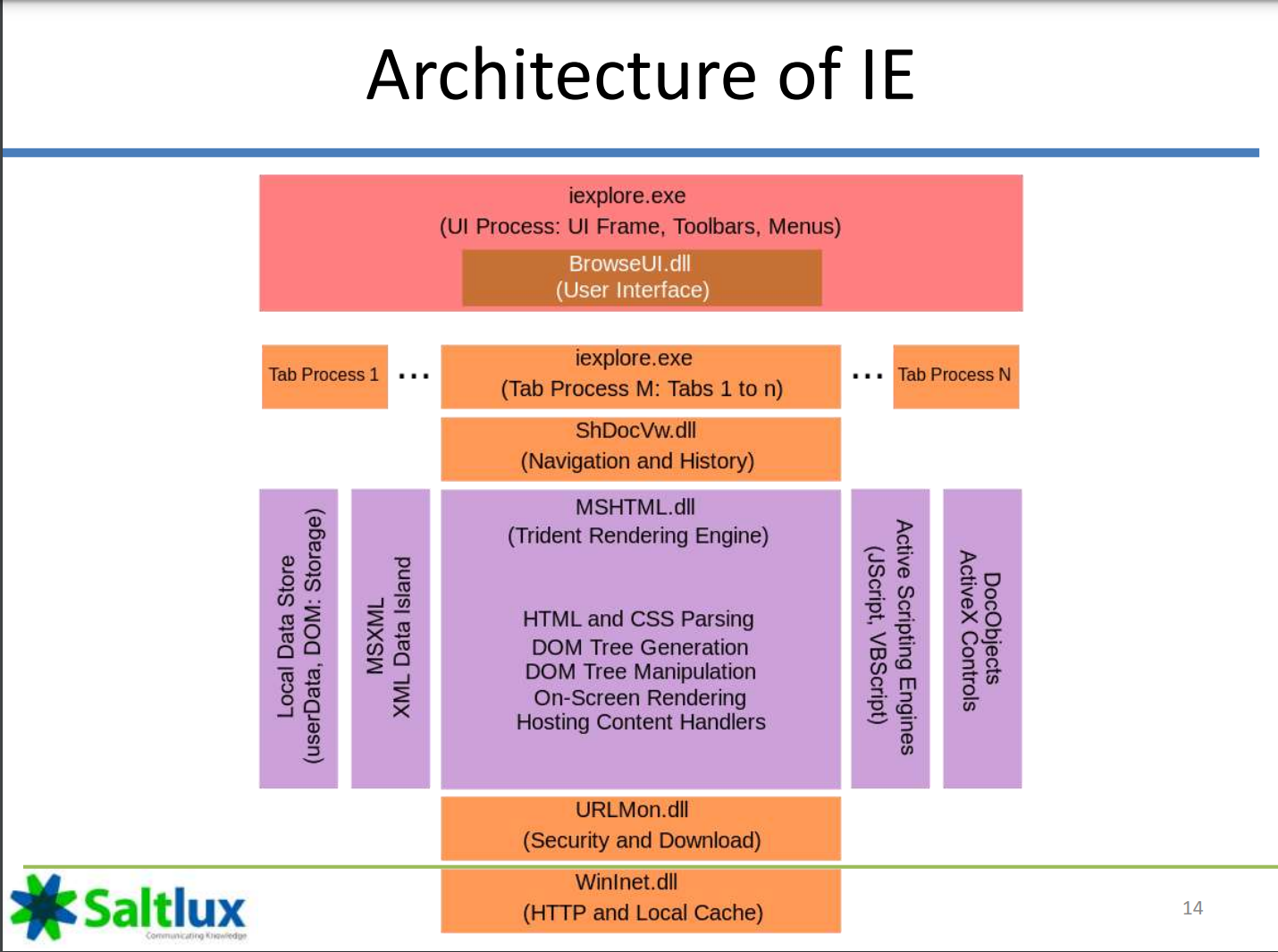
IE:
漏洞利用的学习方法
- 通过patch的方法引入漏洞
- 学习已有的CVE,在两次commit之间找到漏洞点,可能有PoC
步骤:
- 通过patch和commit hash编译
- 通过patch找到漏洞位置
- 定位漏洞调用链,找到触发方法。可以用工具ag来定位ag
- 编写exp
- getshell.一般通过JIT.
V8
v8是chrome里的js引擎,负责执行js代码。
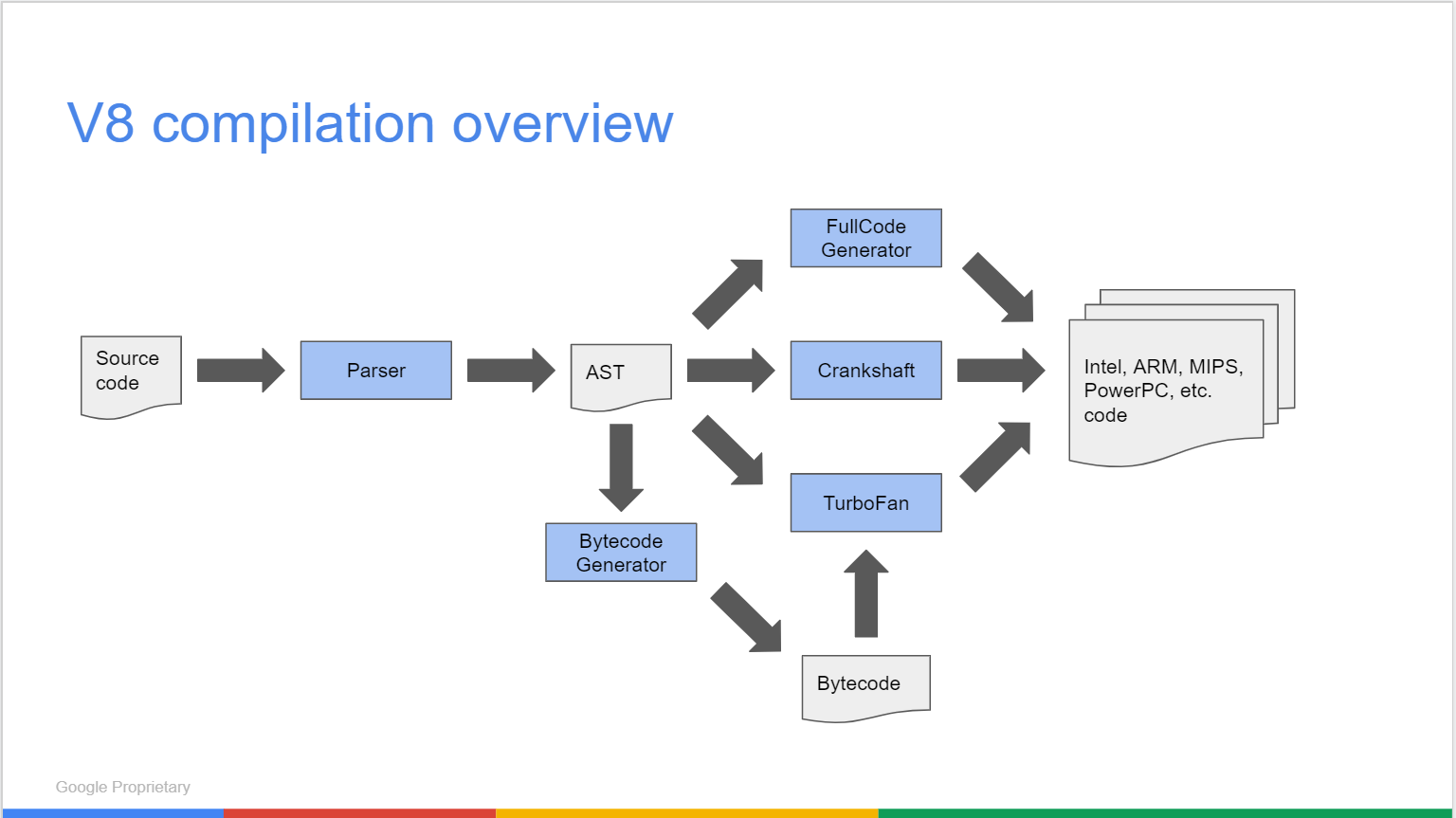
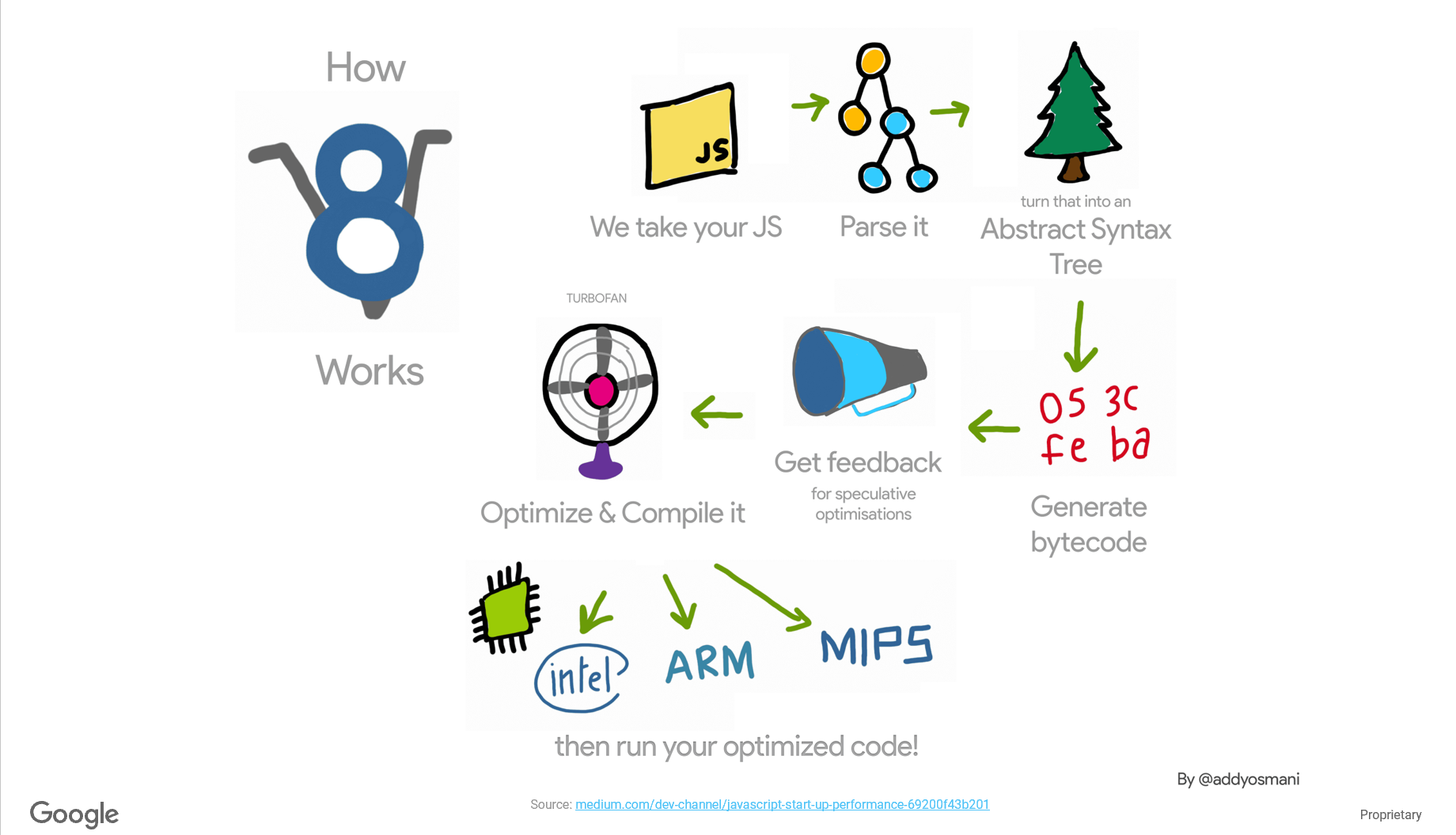
编译器流程
v8编译器的整体流程如下,输入的js代码通过Parser解析得到AST(抽象语法树),AST再生成字节码,字节码经过优化转换成汇编码。
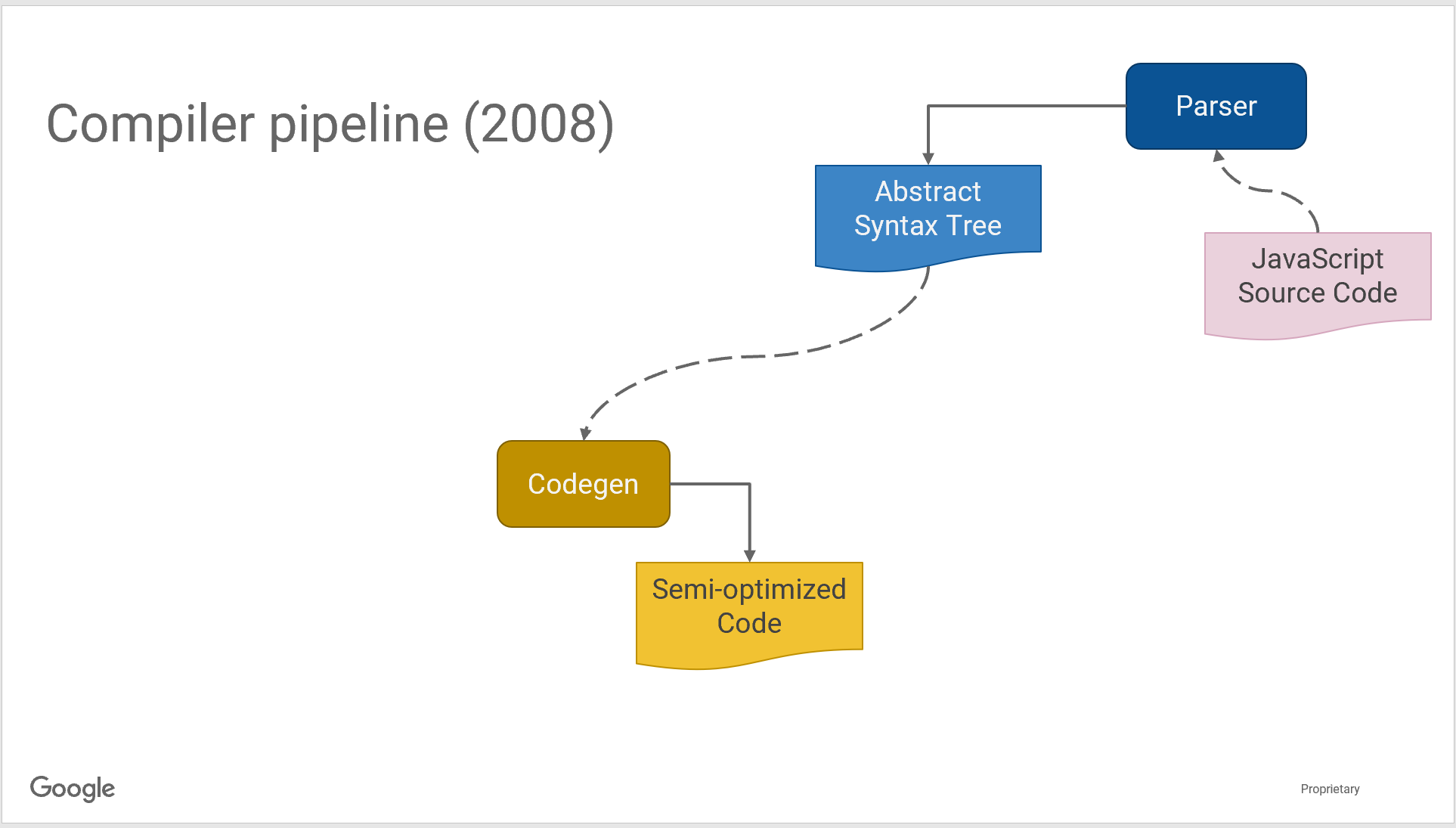
编译器历史
参考google的docTurboFan: A new code generation architecture for V8以及An overview of the TurboFan compiler
2008初代的编译器很简单,语法树半优化后直接产生汇编码(JIT)
2010年,用于优化hot-code的Crankshaft被引入。关于Crankshaft可以参考A New Crankshaft for V8,它显著提升了计算密集型的js应用的性能(甚至可达2倍以上)。这个组件的想法是优化经常执行的代码,对于不常运行的代码则不进行优化。
Crankshaft有四个基本组件:
- 一个base compiler用于所有的代码初始化。它产生代码时不会进行过度优化。
- 一个runtime profiler,监控运行系统,识别出hot code
- 一个optimizing compiler,重新编译hot code。
2014年引入了TurboFan来取代古老的Crankshaft。使用轻量化的汇编器的原因是:1. 解释字节码 2. code stubs和builtin处理 3. asm.js和wasm的处理。
这里先插入一下codestubAssembler的概念,传统的js的builtins是使用不同的汇编进行编写的,这样在不同架构下使用的时候性能表现很好(因为针对不同的架构可以使用不同的汇编优化),但是这样也使得每次写入一个新的Builtin都得适配不同的架构。
codestub的目标就是实现人工编码的性能而不需要适配每种架构。一个轻量的汇编语言在Turbofan的顶端被构建出来,这个API可以产生Turbofan的机器级别的IR,从而被Turbofan使用来对所有平台产生性能较好的机器码。
注意CSA是一个C++的用于产生IR的API,这些IR之后会被编译为机器码到指定架构使用。
再插播一下wasm,之前只是简单知道是类似汇编的语言,详情参考这篇文章WebAssembly简介。wasm是在浏览器中运行的原生代码,汇编语言经过汇编器的翻译可以得到机器码,不同的架构使用不同的汇编和机器码。而wasm并不完全是一种汇编语言,而是一个编译中间层,其可以和js相互调用,可以通过c/c++/rust等编译得到,同一份代码可以在不同架构上被翻译为不同的机器码运行,其具有良好的移植性。
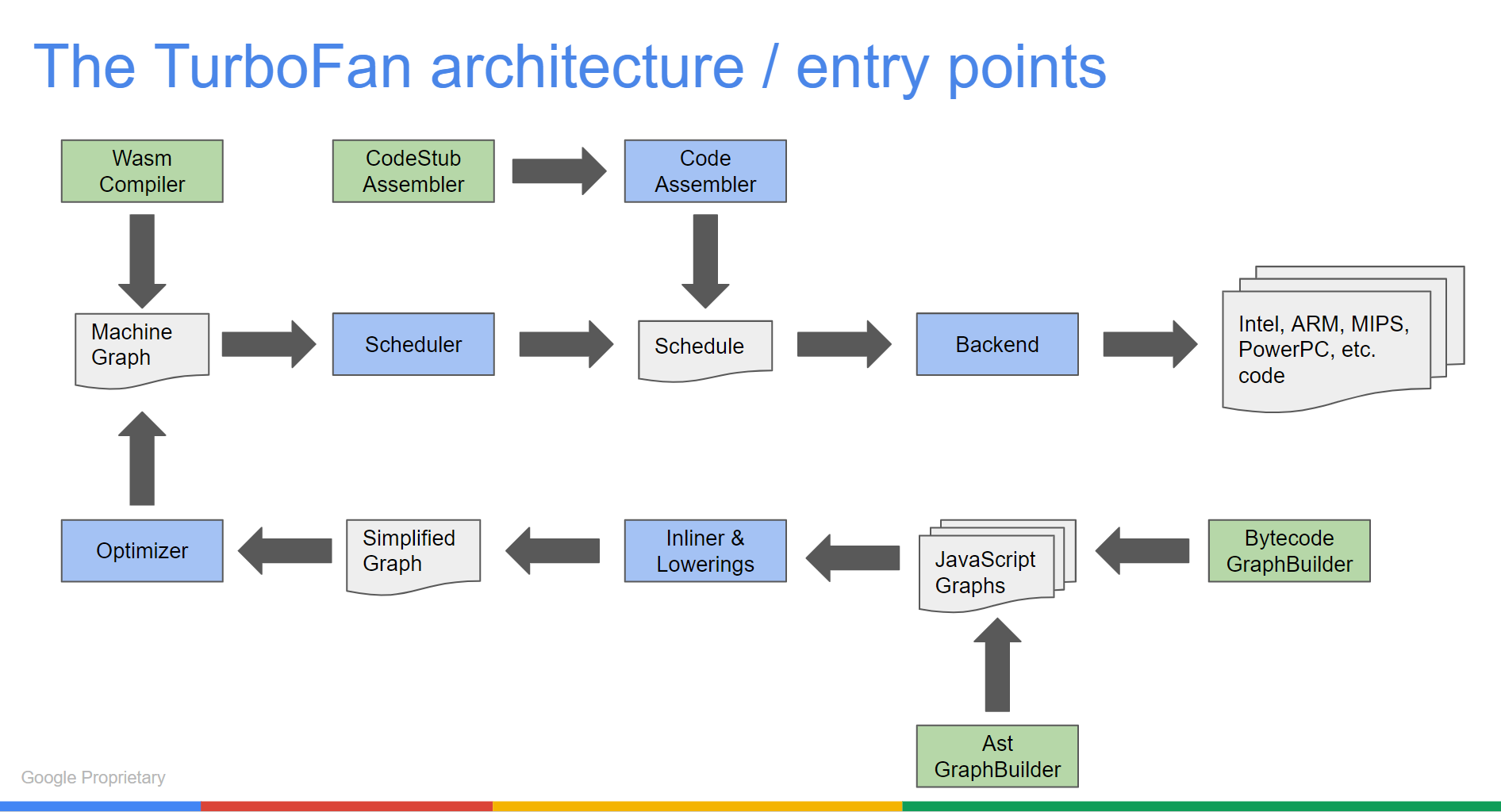
Turbofan的结构如下,其中很多结构不清楚,inliner猜测是inline caching,lowerings猜测是Simplified lowering,我们先看后者。
参考V8-TurboFan编译器引擎介绍,simplified lowering是优化边界检查使用的。其实现了TurboFan Redundant Bounds and Overflow Check Elimination中的想法,通常来说我们在对JS Object进行边界检查的时候会挨个检查index和length的关系,以确保我们只能访问到backing store的数据。假如说idx的范围是[0,length-1],在我们检查arr[i+2]发现并没有越界的情况下,arr[i]和arr[i+1]就没有必要再做越界检查。正是基于这样一个想法,在边界检查时进行了边界检查的消除。
1 | void VisitCheckBounds(Node* node, SimplifiedLowering* lowering) { |
inline caching顾名思义是使用缓存的方式进行优化,以下面一个直观的代码为例,我们定义一个printUserName函数,定义一个对象,之后将其作为参数传进函数中进行调用,当我们连续多次调用同一个参数相同的函数,编译器就将我们的调用函数内联为实际调用的结果,这样就不必每次做编译。

Hidden classes是v8进行对象属性位置查找的一种方式。js作为一种动态语言其对象的性质和静态语言相差很大。我们知道Js的属性可以在实例化之后添加或者删除,比如下面的代码中year这个属性是在我们实例化之后才添加进去的,这样就导致对象寻址变得非常困难。js使用Hash Funtion的方式管理对象属性值在内存中的位置。对于像java这样的静态语言,对象的属性对应类的属性,并不能动态增加和删除(只能通过继承的方式编写子类),java对象的属性值内存布局相对固定,详情可以参考What do Java objects look like in memory during run-time?。通过哈希表查询的方式使得js的属性查询速度非常慢,因此v8引入了Hidden classes。
1 | var car = funtcion(make, model){ |
Hidden classes和使用固定对象属性偏移的Java有点像,只不过这个偏移是在runtime生成的。v8为每一个obj都attach了hiddent classes用于优化属性访问。
这里我们举个栗子。
1 | function Point(x,y) { |
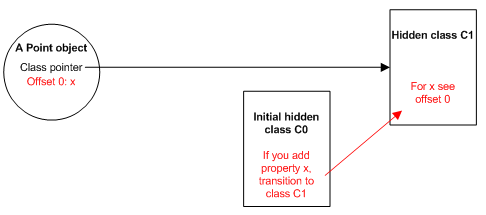
当新函数Point声明之后(不包括里面属性的赋值),v8就会创建一个hidden class C0,这个函数对象的类指针指向C0.

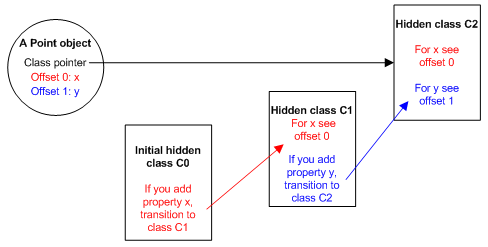
当函数中的第一行this.x=x执行之后,会产生新的hidden class C1,在C1中,offset为0的位置即属性x存储的位置,Point对象也由原来的指向C0变为指向C1。这个过程被称为class transition.这种hidden class可以被使用同样方式创建的对象所共享。如果两个对象共享同样的hidden class并被加入了相同的属性,那么transition保证它们会转换成相同的新的hidden class,并得到相同的优化代码。
同样的过程也会发生在this.y=y的执行过程中。
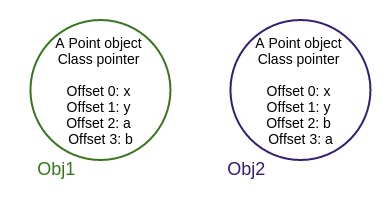
hidden class的生成依赖于属性attach到对象的顺序,参看下面的例子.
1 | function Point(x,y) { |
一直到obj1.a=5前,obj1和obj2都一直共享相同的hidden class。在赋值之后二者transition的结果发生了变化。在此基础上,我们再来研究一下inline caching看共享hidden class的意义。
当一个obj中的方法被调用时,v8都需要通过Hidden class查询的方式确定访问特定属性的偏移,如果连续两次对同一个hidden class的方法调用成功,那么属性的偏移就直接加入到了class pointer上,之后的访问就会假设hidden class没有发生改变,直接从上一次查询的结果中获取偏移,这样提高了代码的执行速度。这也是为什么相同类型的obj共享hidden class是如此重要。如果他们属性相同但是Hidden class不同,那么v8就无法对这两个对象做inline cache,属性的偏移在class中是不同的。
当这种假设出错,v8就会de-optimize,然后回退到之前hidden class检查过的版本。参考DLS Keynote: Ignition: Jump-starting an Interpreter for V8
的内容可以看到所谓的hidden class应当是以map的形式标识的.
上面这篇文章提到了deoptimization,用于优化过程中一些假设判断失误进行回退,那么我们秉持着哪里不会查哪里的原则看下v8是如何进行优化和反优化的。
google sildes的这篇文章介绍了v8的去优化Deoptimization in V8。v8通常是对见到的cases进行优化,past cases通过typer feedback vector进行记录。优化过的代码通过feedback动态验证猜想。假如动态检查失败,去优化器反优化代码:
- 抛弃优化过的代码
- 在优化过的栈和寄存器中创建解释器frame
- 跳转到Interpreter
具体地:
- 将当前栈帧和HW寄存器文件读到缓冲区中
- 构造Interpreter frame,使用优化过的栈帧和寄存器
2.1 使用编译器提供的信息
2.2 这些信息包括:要恢复的共享函数和字节码的偏移量、硬件寄存器/栈slots中的参数位置、解释器中的寄存器/栈slot的位置、内联的frame
2.3 Materializes通过转义分析编译掉的对象
2.4 跳到解释器没有被patch的地方
Turbofan中的去优化分为eager和lazy两部分。
对于eager deoptimization:在每个潜在的去优化节点前插入checkpoint node到影响链中,基本上是在处理每个字节码之前
对于lazy deoptimization:Attach去优化的状态到每个潜在的调用节点。
在构建图时假如存在许多去优化相关的节点,我们就复用之前frame状态,将状态以树的形式表示出来。
到这里Turbofan的基本组件就比较清晰了。
2016引入了生产中间语言的Ignition
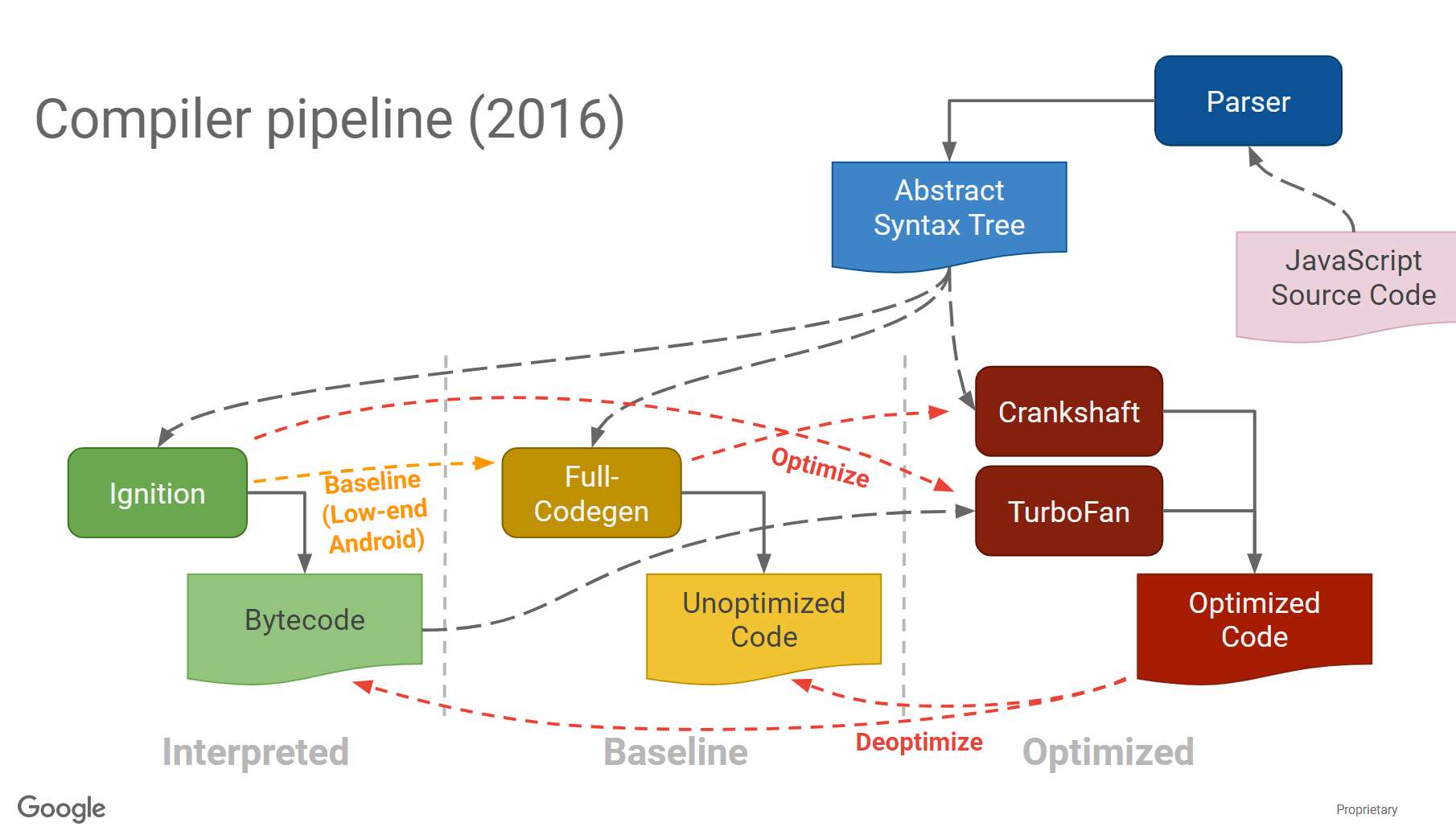
关于Ignition,可以阅读Ignition: An Interpreter for V8 [BlinkOn]。
v8的三大编译器存在着复杂的依赖关系,因此引入了Ignition这个js的字节码解释器。
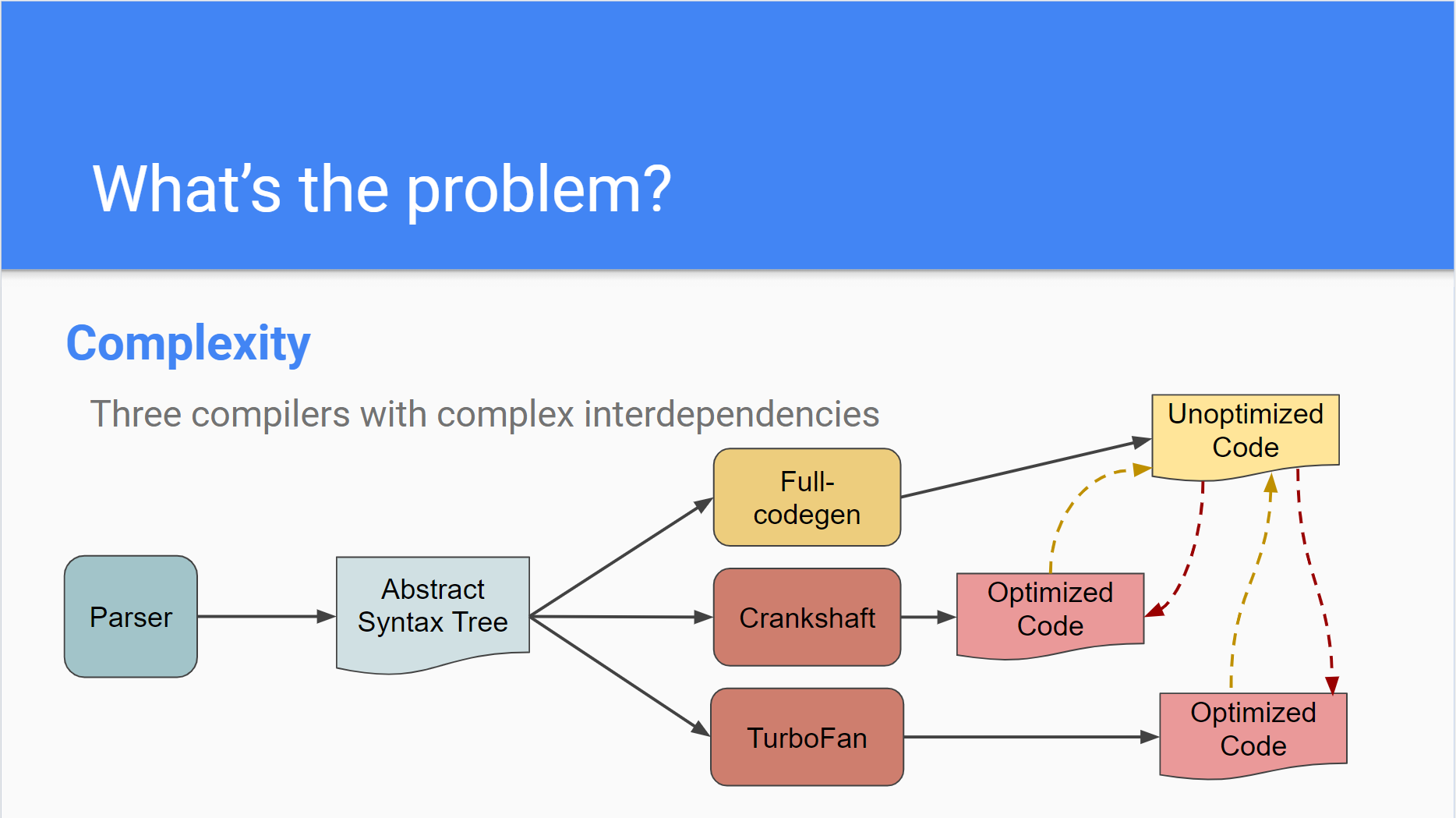
引入之后的pipline如下
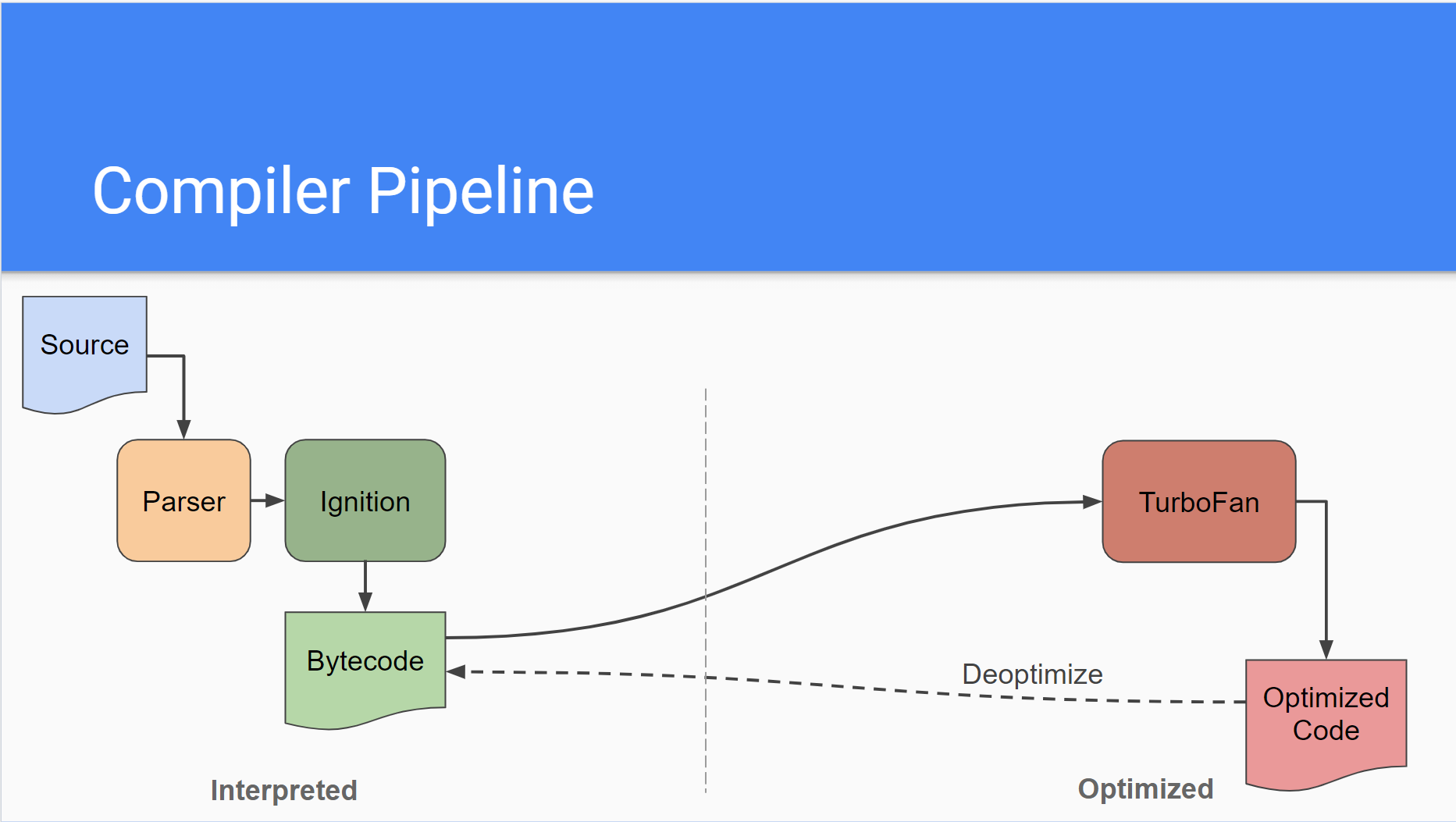

Ignition的字节码表如下

17年之后就移除了Crankshaft和Full-codegen。
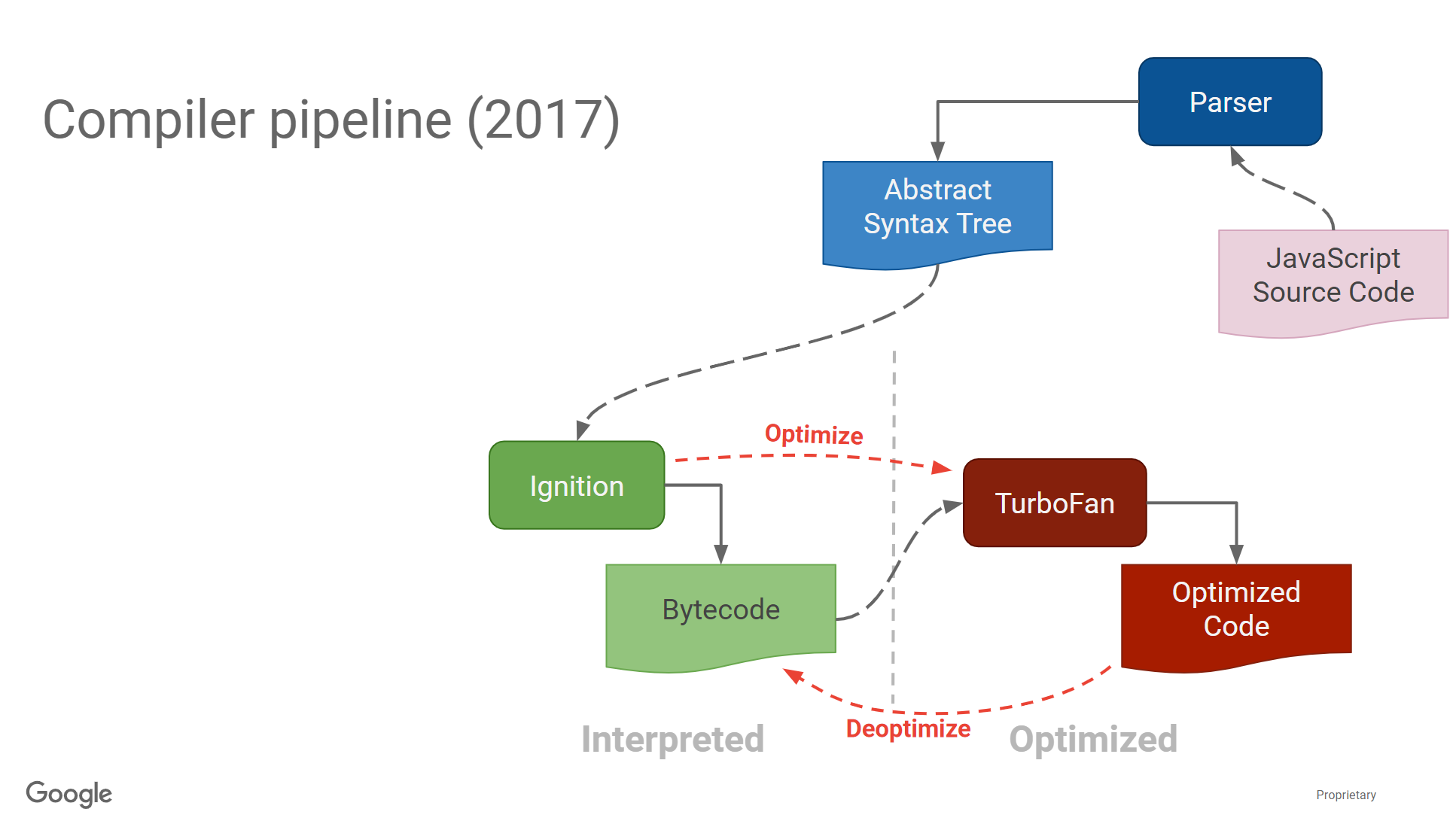
TurboFan
最后重点介绍一下TurboFan。
Sea of Nodes
TurboFan在一个叫做sea of nodes的程序上运行。Nodes可以表示算数运算,load、store、calls和常量等。一共有三种edge:control edges、value edges、effect edges。
control edge和CFG中看到的一样,它们用于分支和循环。
value edges是在Data Flow Graph中的边,它们表示数据的依赖关系。
effect edges标识出读写的状态。以obj[x] = obj[x] + 1为例,其effect chain如下图所示.整个chain为load->add->store
对于想要详细了解的同学,可以参考TurboFan JIT Design
之前在Ubuntu 20.04搭了v8的环境,我们也可以动手看下sea of nodes。由于我用的是最新版本的v8,所以这里似乎已经没有了CheckBounds的消除,原本是参考introduction-to-turbofan进行实验,现在还是依自己得到的结果为准。Moon师傅下午指点了一下俺,终于明白为什么我的图和博客中的不一样了,下面的代码增加了一行%PrepareFunctionForOptimization(opt_me);,是为obj的feedback做初始化,之后的两次函数调用使得feedback填入了值,从而在%OptimizeFunctionOnNextCall(opt_me)调用时做了包含有feedback的优化。
编写如下js代码进行实验,./d8 1.js --allow-natives-syntax --trace-turbo得到turbo json文件,使用python -m SimpleHTTPServer启动一个服务器,访问本地的8000端口即可查看sea of nodes。
1 | function opt_me() { |
Optimization phase
第一个图为BytecodeGraphBuilder,每个阶段后面的编号表示生成的顺序,这个阶段是将js代码翻译为字节码,生成基本的IR图,可以看到最后return前调用SpeculativeNumberAdd来对变量进行加和。
第二个为Inlining,将一些代码内联到调用函数处
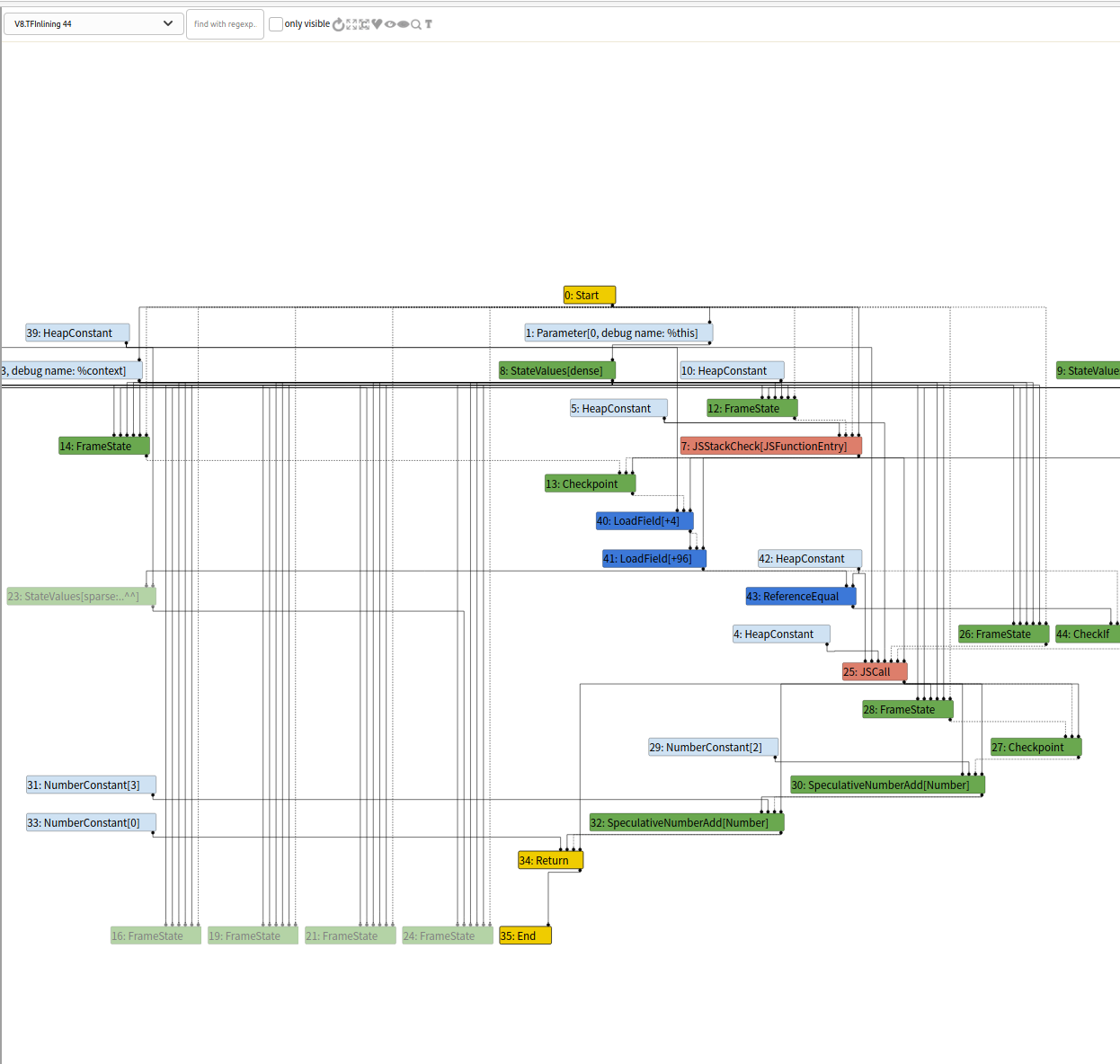
接下来是一个比较重要的阶段Typer phase,在这个阶段会尽可能地推断出节点的类型,这部分的优化代码在OptimizeGraph中
1 | struct TyperPhase { |
在typer.cc中找到对应的函数,会发现它将遍历图上的所有节点,试图优化掉它们。例如在这里当我们的visitor访问到一个JSCall节点之后会调用JSCallTyper,每一个调用的builtin函数都关联了一个Typer,我们的测试代码使用了Math.random,在这里被优化为了PlainNumber这个type。
1 | void Typer::Run(const NodeVector& roots, |
对于TypeNumberConstant类型的节点来说,大部分时候得到的类型都是一个Range。
1 | Type Typer::Visitor::TypeNumberConstant(Node* node) { |
继续来看SpeculativeNumberAdd的节点类型处理,它属于OperationTyper,最终通过Name调用了OperationTyper::NumberAdd(Type lhs, Type rhs),它首先对lhs(left hand side)和rhs(right hand side)两个节点调用SpeculativeToNumber赋值,之后调用NumberAdd进行加和,在这个函数中会对参数类型进行判断,大多数情况下返回PlainNumber类型。
总结一下,我们第一个图中的JSCall(MathRandom)最终会被推断为PlainNumber,NumberConstant[n]且n != -0 & n != NaN的会被推断为Range(n,n),而range(n,n)又会被推断为PlainNumber,SpeculativeNumberAdd(PlainNumber, PlainNumber)会被推断为PlainNumber
1 | //operation-typer.cc |
经过这个阶段之后,图变成了下面这样(注意这里并没有如上文分析的推断结果)
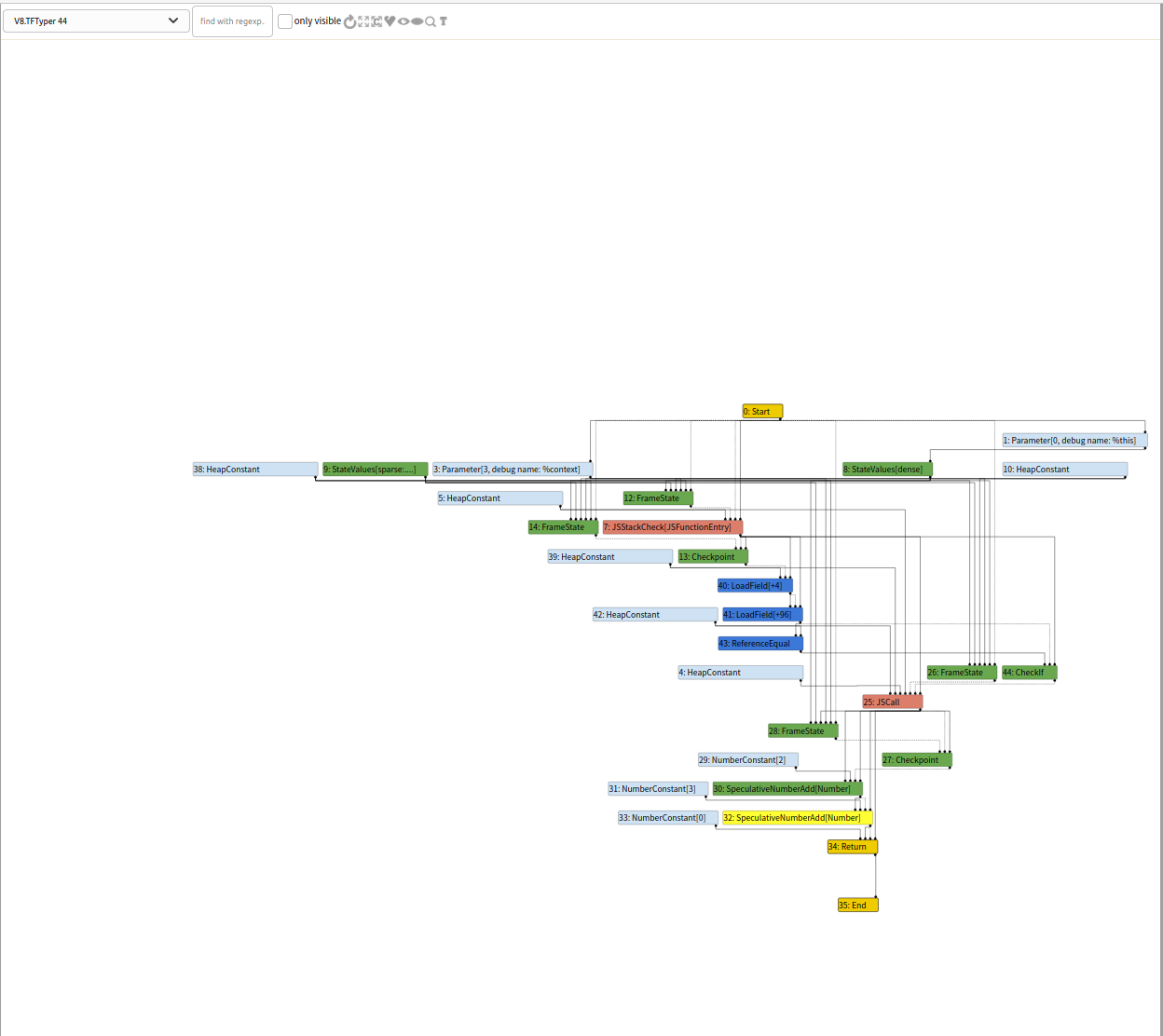
Typer Lowering就在typer phase的后面,这里做了更多的节点消除。我们来看下TypedOptimization以及TypedOptimization::Reduce
1 | bool PipelineImpl::OptimizeGraph(Linkage* linkage) { |
当一个节点已经被访问过,且opcode为IrOpcode::kSpeculativeNumberAdd,则调用ReduceSpeculativeNumberAdd(node).在这个函数中首先取节点的hint属性,我们的lhs和rhs都是PlainNumber,都有NumberOperationHint::kNumber的hint属性,因此最终执行replace将原本的kSpeculativeNumberAdd节点替换为了NumberAdd节点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32Reduction TypedOptimization::Reduce(Node* node) {
DisallowHeapAccessIf no_heap_access(!FLAG_turbo_direct_heap_access);
switch (node->opcode()) {
//..
case IrOpcode::kSpeculativeNumberAdd:
return ReduceSpeculativeNumberAdd(node);
//..
}
return NoChange();
}
//
Reduction TypedOptimization::ReduceSpeculativeNumberAdd(Node* node) {
Node* const lhs = NodeProperties::GetValueInput(node, 0);
Node* const rhs = NodeProperties::GetValueInput(node, 1);
Type const lhs_type = NodeProperties::GetType(lhs);
Type const rhs_type = NodeProperties::GetType(rhs);
NumberOperationHint hint = NumberOperationHintOf(node->op());
if ((hint == NumberOperationHint::kNumber ||
hint == NumberOperationHint::kNumberOrOddball) &&
BothAre(lhs_type, rhs_type, Type::PlainPrimitive()) &&
NeitherCanBe(lhs_type, rhs_type, Type::StringOrReceiver())) {
// SpeculativeNumberAdd(x:-string, y:-string) =>
// NumberAdd(ToNumber(x), ToNumber(y))
Node* const toNum_lhs = ConvertPlainPrimitiveToNumber(lhs);
Node* const toNum_rhs = ConvertPlainPrimitiveToNumber(rhs);
Node* const value =
graph()->NewNode(simplified()->NumberAdd(), toNum_lhs, toNum_rhs);
ReplaceWithValue(node, value);
return Replace(value);
}
return NoChange();
}
此阶段后的图如下。
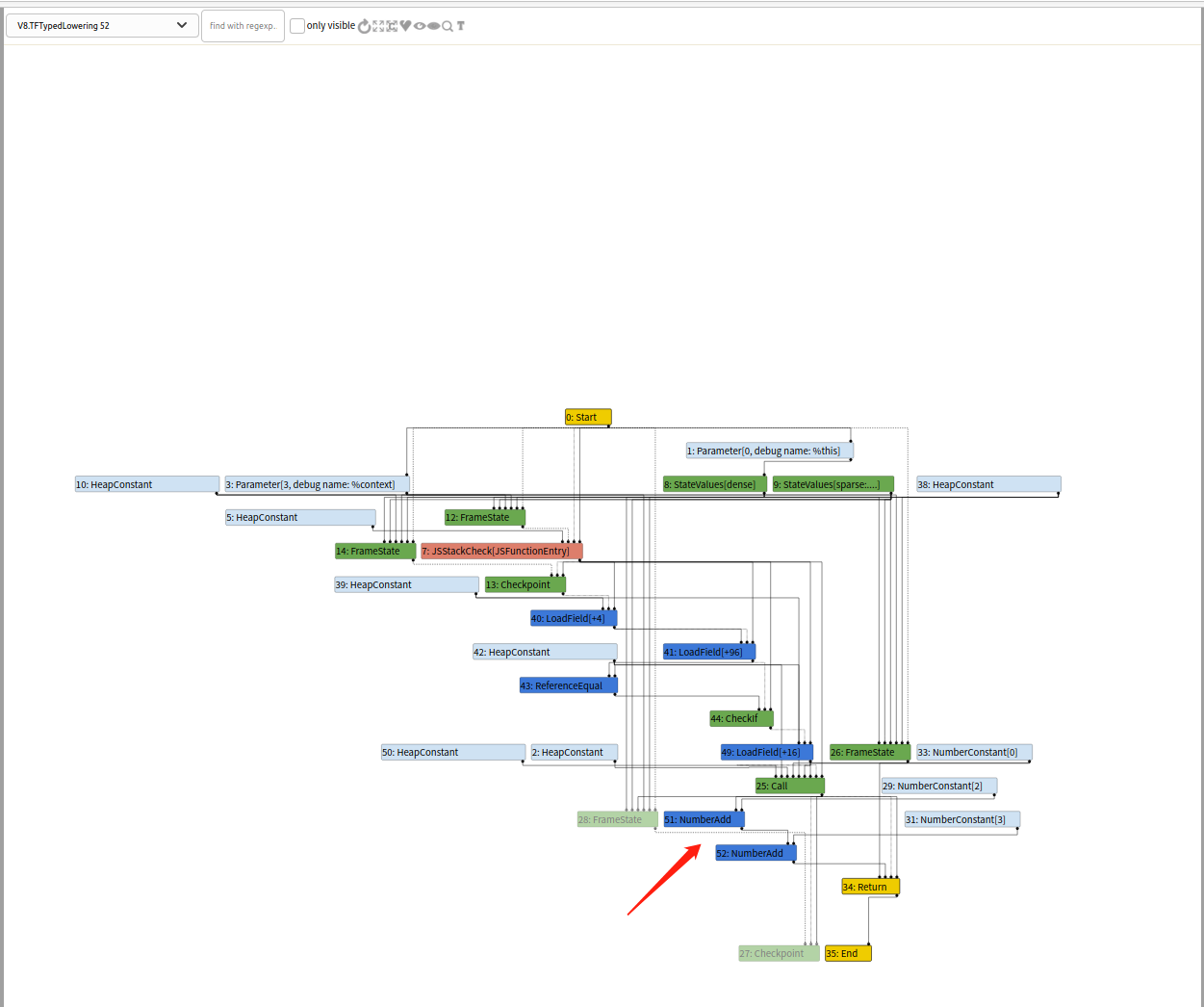
对于JSCall节点,JSTypedLowering::ReduceJSCall函数最终创建了LoadField节点并将JSCall的opcode转换为Call的opcode(注意这里的node没有变化,只是opcode发生了变化)。
1 | Reduction JSTypedLowering::ReduceJSCall(Node* node) { |
Range types
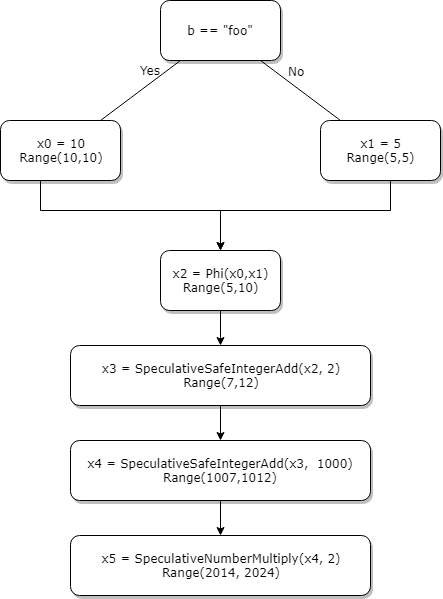
考虑下面的例子,根据SSA(IR的一种规范,可以参考LLVM SSA 介绍)。当b=="foo"时,x=5,否则x=10,因为在SSA里只能单变量赋值,因此这里我们引入了x0和x1,并使用Phi函数进行取值。
当对phi的返回值进行类型推断时,我们可以看到x2要么为5要么为10,那么x2很明显是一个(5,10)的union。我们做个符合SSA形式的流程图。看下v8里对这个节点进行推断的代码。
1 | function opt_me(b) { |
这里的代码和我们想法相同,对可能的取值取union。1
2
3
4
5
6
7
8Type Typer::Visitor::TypePhi(Node* node) {
int arity = node->op()->ValueInputCount();
Type type = Operand(node, 0);
for (int i = 1; i < arity; ++i) {
type = Type::Union(type, Operand(node, i), zone());
}
return type;
}
后面我本地的图生成的和博客不同,因此以博客的为准,我又知道为什么不一样了,我们需要点下toggle types这个Button,才能在Node里显示出判断的range范围,这里以我之后的例子做个图,下下图为博客里的图。
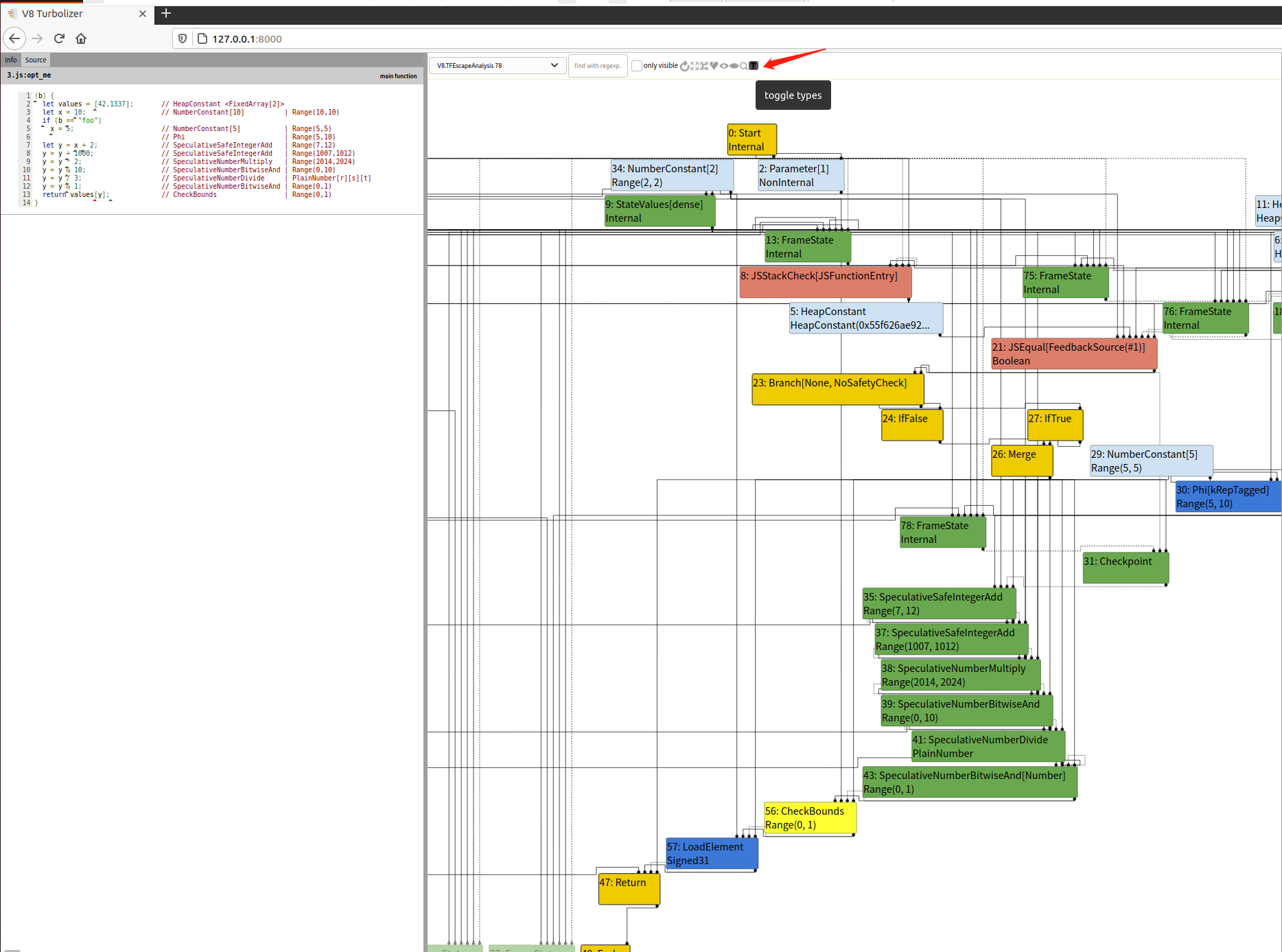
在源码中没有找到SpeculativeNumberAdd函数,目测是个opcde,在SIMPLIFIED_SPECULATIVE_NUMBER_BINOP_LIST表中已经定义好了函数地址,通过table[idx]的方式直接调用。而根据作者的说法,最终会调用到NumberAdd,或许Speculativexxyyzz就会调用xxyyzz?这里不太明白Mark一下.AddRanger函数为Range标明了范围。
1 | Type OperationTyper::SpeculativeSafeIntegerAdd(Type lhs, Type rhs) { |
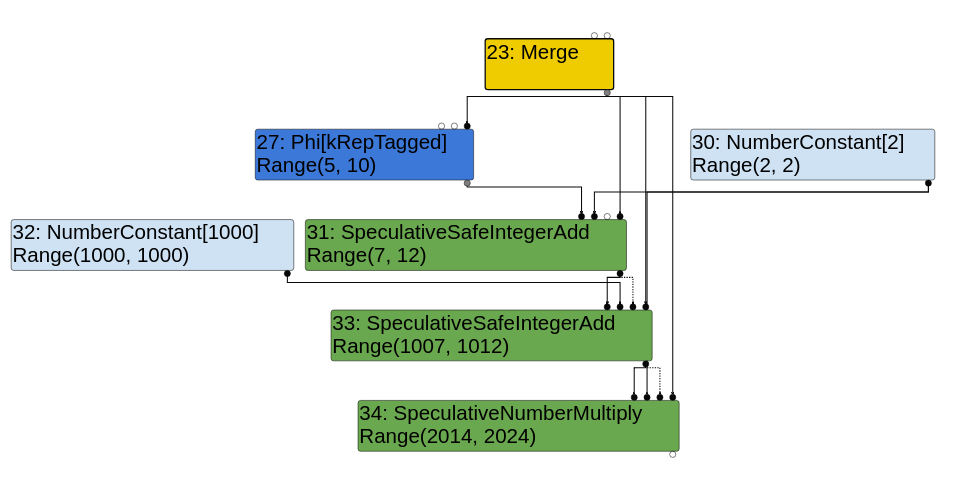
CheckBounds nodes
考虑如下的代码:
1 | function opt_me(b) { |
最后我们对values[y]取值时需要检查y的范围以保证不会越界读写,因此在IR图中增加了一个CheckBounds节点.仔细观察的话可以发现其取值为(0,1)。LoadElement的一个输入是类型为FixedArray[2]的HeapConstant,这就引出了我们的最后一部分Simplified lowering
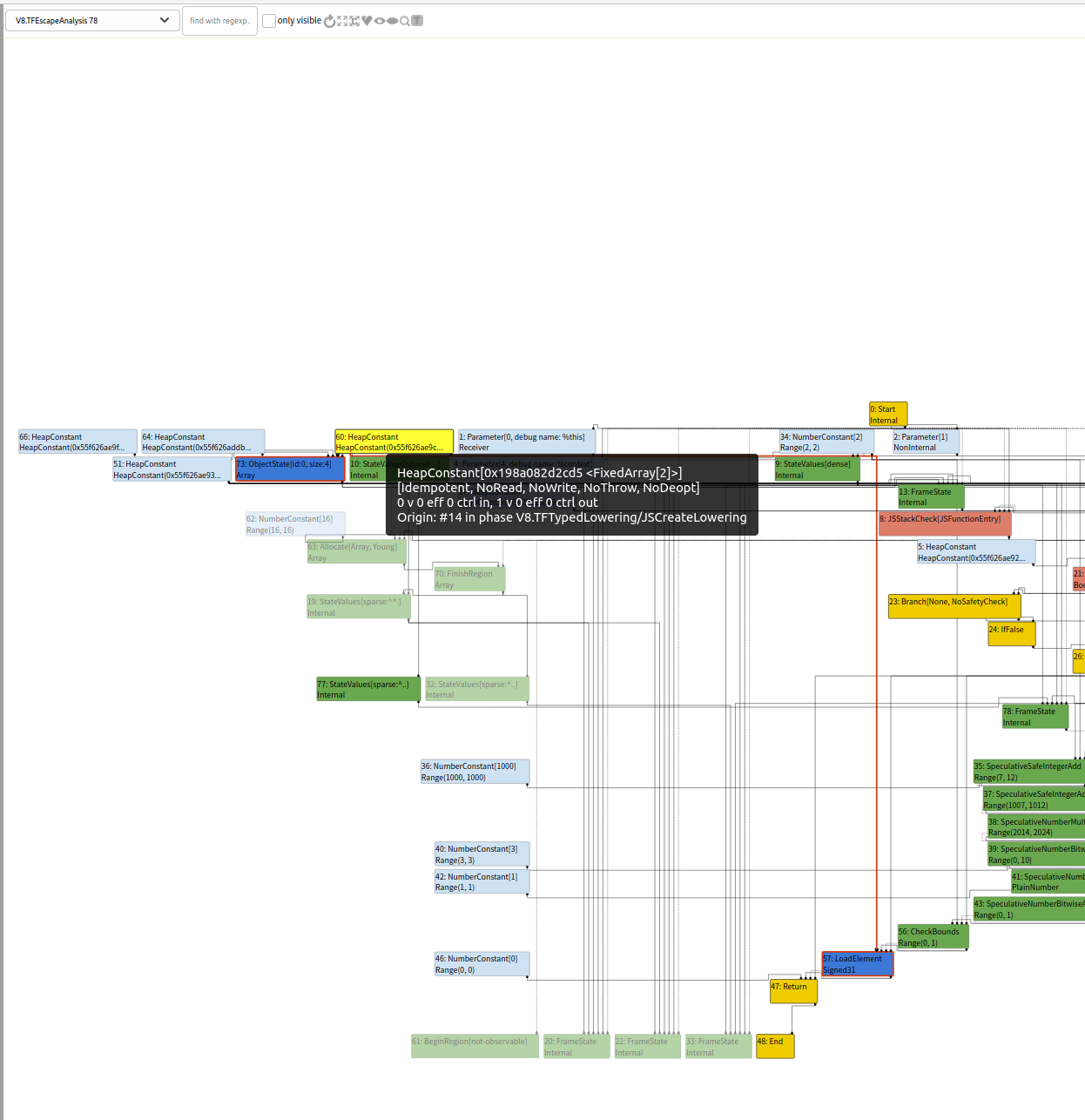
Simplified lowering
这部分博客和本地的代码无法对应,因为最新的v8去掉了CheckBounds elimination,后面会分析一些与之相关经典的漏洞介绍为什么这个机制这么容易被利用。这里我们学习一下之前版本这里的设计。当我们发现index范围满足[0,index_max] && index_max < length_min时,我们可以对这个节点进行消除。之前设置的参数v8_untrusted_code_mitigations主要用于lowering->poisoning_level_ == PoisoningMitigationLevel::kDontPoiso条件的判定,具体原因可以参看浅析 V8-turboFan(上),主要代码是下面FLAG的赋值。默认配置导致我们无法得到正确的load_poisoning,从而无法启动checkBounds的优化。
1 | void VisitCheckBounds(Node* node, SimplifiedLowering* lowering) { |
addition opcodes
我们根据几个例子来看不同情况下底层使用的opcode。
补一下js的基础知识箭头函数。
- 箭头函数表达式的语法比函数表达式更简洁,并且没有自己的this,arguments,super或new.target。箭头函数表达式更适用于那些本来需要匿名函数的地方,并且它不能用作构造函数
下面的函数在经过多次调用后推断i为一个小整数,因此使用AddSmi这个ignition opcode(前面我们提到ignition解释器产生字节码)。IR图里的加使用SpeculativeSafeIntegerAdd
1 | let opt_me = (x) => { |
1 | Bytecode Age: 0 |
在这个例子中x加和的对象为固定值1000000000000,它不能被小整数所表示,因此IR图为SpeculativeNumberAdd.
1 | let opt_me = (x) => { |
在这个例子中y+100的值需要进行推断,这里使用SpeculativeSafeIntegerAdd,在simplified lowering阶段,TurboFan确定y+100是两个整数的和,因此底层的node为Int32Add1
2
3
4
5
6
7let opt_me= (x) => {
let y = x ? 10 : 20;
return y + 100;
}
opt_me(true);
%OptimizeFunctionOnNextCall(opt_me);
opt_me(false);
下面的例子中y是一个复杂的对象,这里只能使用性能较差的jsAdd。
1 | let opt_me = (x) => { |
在这个例子中y+1000000000000不能被Int表示出来,并且由于我们可以确定y是整数,在IR图中使用NumberAdd节点进行计算
1 | let opt_me = (x) => { |
TurboFan优化总结
优化的手段有:
- Inline 内联函数调用
- trimming 删除未到达的节点
- type 类型推断
- typed-lowering 根据类型将表达式和指令替换为更简单的处理
- loop-peeling 取出循环内的处理
- loop-exit-elimination 删除loop-exit
- load-elimination 删除不必要的读取和检查
- simplified-lowering 使用具体的值来简化指令
- generic-lowering 将JS前缀指令转换为更简单的调用和stub调用
- dead-code-emilination 删除不可达的代码
v8对象
参考a-tour-of-v8-object-representation,v8中一个典型的对象布局如下。
大多数的对象将他们的属性放到一块区域中,如这里的a和b。所有的block都有一个指向map的指针,这个map代表了对象的结构。非对象内部的其他属性通常存放在一个overflow array中,如这里的c和d。数字式的属性通常存放在其他的连续内存的数组中。
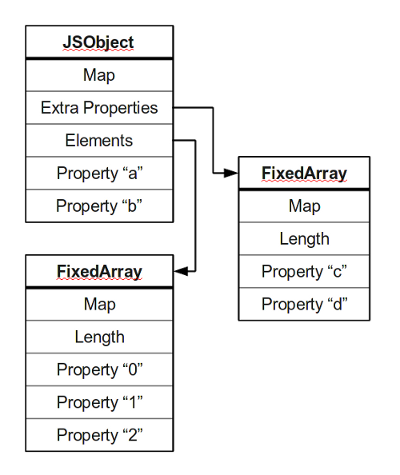
v8对象的定义非常灵活,一个对象基本上就是属性的集合,基本上是key-value的字典对,可以通过一下两种方式访问
1 | obj.prop |
根据标准,属性总是以字符串形式存在,因此如果使用一个不是string类型的属性,他会隐式地转换为字符串类型,正因为此,可以使用负数和小数对数组进行访问。
1 | obj[1]; |
js中的Arrays又多了一项特殊的属性length.数组中大多数属性都是以非负整数命名。length返回数组中可以访问的最大索引+1,如:
1 | var a = new Array(); |
除此之外数组和其他类型的对象都没有什么大的不同,函数也是对象,函数对象的length为函数形参的数量。
Dictionary mode
v8使用哈希表来表示复杂的对象,访问哈希表的速度要远慢于访问已知偏移的对象。
哈希表的工作原理:v8中有许多种不同的方式表示一个string,最常见的property的名字是一个ASCII的字符串,所有的字符连续排列。
strings时不可修改的,但是hash code这个field是可以修改的,因为它是被计算出来的值,用于访问属性的字符串被称为symbols,这些字符串都是独特的,因此如果一个non-symbol string要用于访问property,它要先进行独特化。
v8的哈希表包括key和value.最开始时,所有的keys和values都是undefined。当一个key-value被插入进来,key的hash值就会被计算出来,hash code的低位将会作为开始插入的索引,如果该索引已经有数据则插入到下一个索引(模n,n为表空间大小)。
由于symbol strings是独特的,这些strings的hash code至多计算一次,之后比较keys相等的操作通常都比较快,但是这些开销仍然很大,当对属性进行读写时的速度很慢,V8尽可能避免使用这种方法进行表示
1 | 0:map(string type) |
Fast,in-object properties
这部分涉及到了之前我们介绍的Hidden class概念,为了加速访问速度,让obj的内存布局在运行时也可以像静态语言一下规律排列,我们使用maps标识不同的对象,我们可以将maps理解成一个descriptors table,每个property都对应一个entry。Map还包含了其他的信息,比如obj的size,指向constructor和prototypes的指针,但是我们主要关注descriptors。拥有相同结构的对象通常共享相同的map。Point的一个结构化的实例可能会共享如下所示的map。
1 | function Point(x, y) { |
我们可以想到并不是所有的Point的实例都有相同的属性集合,当一个Point对象刚分配的时候(在构造函数执行前),它没有任何属性M2并不能精确地描述它的结构。此外,我们可以在构造函数执行后随时添加一个新的属性到Point对象中。
v8使用transitions的方式处理这种情况,当增加一个新属性的时候,如果不是必须创建一个新的map我们是不希望这样做的,我们倾向于使用现有的map,transition descriptors指向这些其他的maps。1
2
3
4Map M2
object size: 20 (space for 2 properties)
"x": FIELD at offset 12
"y": FIELD at offset 16
因此可能存在如下的转变
1 | <Point object is allocated> |
假如说对一个使用M2 map属性的对象添加新属性,但是该属性推迟赋值,则会出现下面这种情况。因为z属性从来没有被分配过,我们创建了M2的拷贝M3,增加了一个新的filed描述符,并且为原来的M2 map增加了一个TRANSITION描述符。增加一个transition是唯一一种修改map的方式,大多数时候map都是无法修改的。
如果赋值的顺序不同,或者赋值的顺序混乱,又或者删除了其中的属性,则v8只能将obj放到hash表中
1 | Map M2 |
In-object slack tracking
v8使用In-object slack tracking来判断为一个对象的实例分配多少空间。最开始,constructor分配的对象被分配了一个巨大的空间:足够32个fast properties存储。一旦使用相同的构造器构造出一定数量的obj,v8通过遍历这些原始obj的map的transition tree。新的obj就可以精准地分配足够空间来存储properties(大于其数量的最大值)。也有一些有趣的trick来对原始obj进行resize。当原始obj第一次被分配时,它们的fileds将被初始,这样在gc看来它们就是空闲的空间。但是gc不会真的将他们看作空闲空间,因为maps标识了对象的大小。然而当slack tracking process
结束后,新的实例的size就会写入到transition tree的maps中,因此有这些maps的obj大小显著减小。因为unused filed已经看上去像是空闲space,最开始的obj不需要被修改。
在这个过程结束后再增加新的property,会使用overflow array来存储extra property,这里就会使用realloc来扩大空间。
= =本来这里已经写完了,但是因为笔记误删(vscode未成功保存导致文件为空)这部分又得重新写,因此比之前要写的简单一点
Methods and prototypes
v8存放methods时不能将其看成in-object的属性,否则开销太大,这里借鉴了c++的vtable的思想,关于vtable可以参见Understandig Virtual Tables in C++,v8在maps里使用constant_function表示方法,只有constant_function相同的maps才可以相互transition。
1 | function Point(x, y) { |
如下图所示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<Point object is allocated>
Map M0
"x": TRANSITION to M1 at offset 12
this.x = x;
Map M1
"x": FIELD at offset 12
"y": TRANSITION to M2 at offset 16
this.y = y;
Map M2
"x": FIELD at offset 12
"y": FIELD at offset 16
"distance": TRANSITION to M3 <PointDistance>
this.distance = PointDistance;
Map M3
"x": FIELD at offset 12
"y": FIELD at offset 16
"distance": CONSTANT_FUNCTION <PointDistance>
v8还提供了一种原型的方法让我们使用,prototype可以看作是一个root object,v8的obj认为其包含自身所有的属性
1 | function Point(x, y) { |
Numbered properties: fast elements
主要有三种类型fast small integers\fast doubles\fast values,当数据类型无法表示smi时会进行转换,当访问的Index和长度相差过多时会降级到dictionary mode
1 | // This will be slow for large arrays. |
对象模型
首先是一个继承关系的图
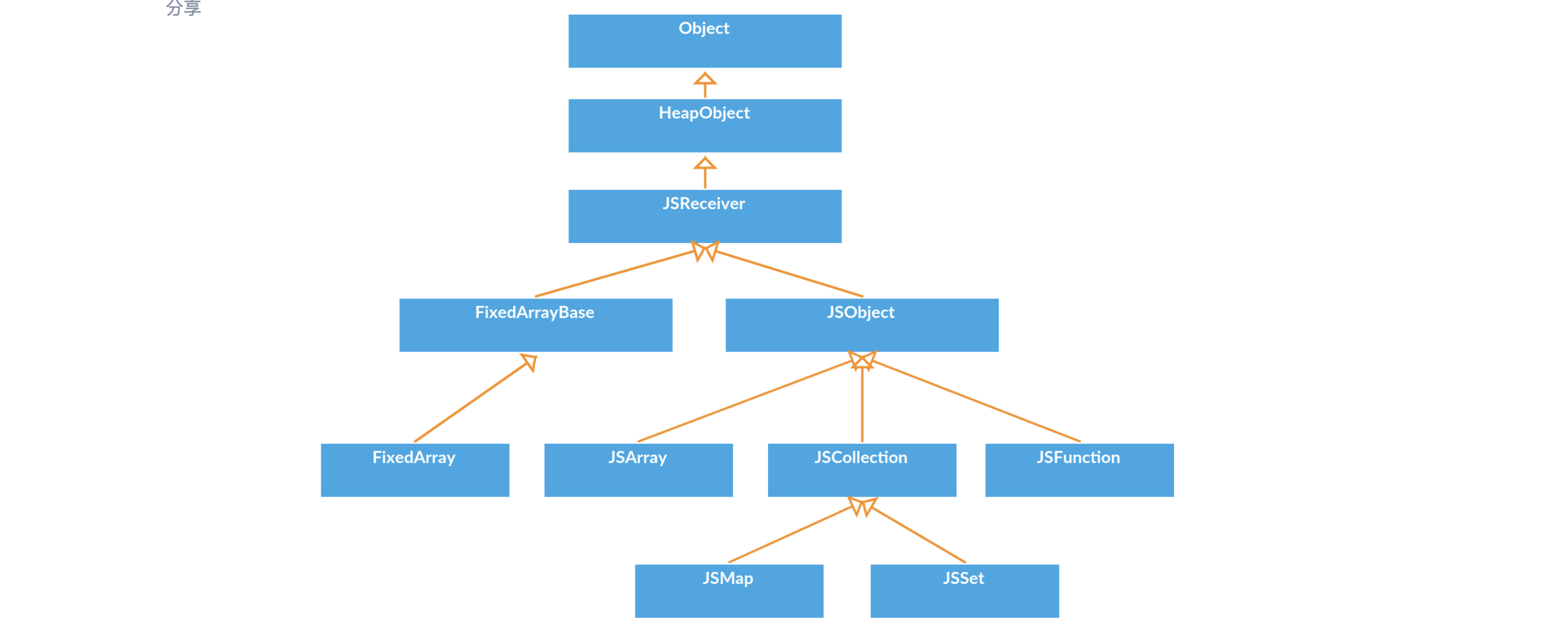
Object && Tagged Object
Smi
Smi是Unbox的整数,在32位系统下是带符号的31位;64位系统下是带符号的32位。
Smi直接存储在obj中,LSB=1时表示指针,否则为数字。
HeapObject
HeapNumber继承自HeapObject,对象的值为double。
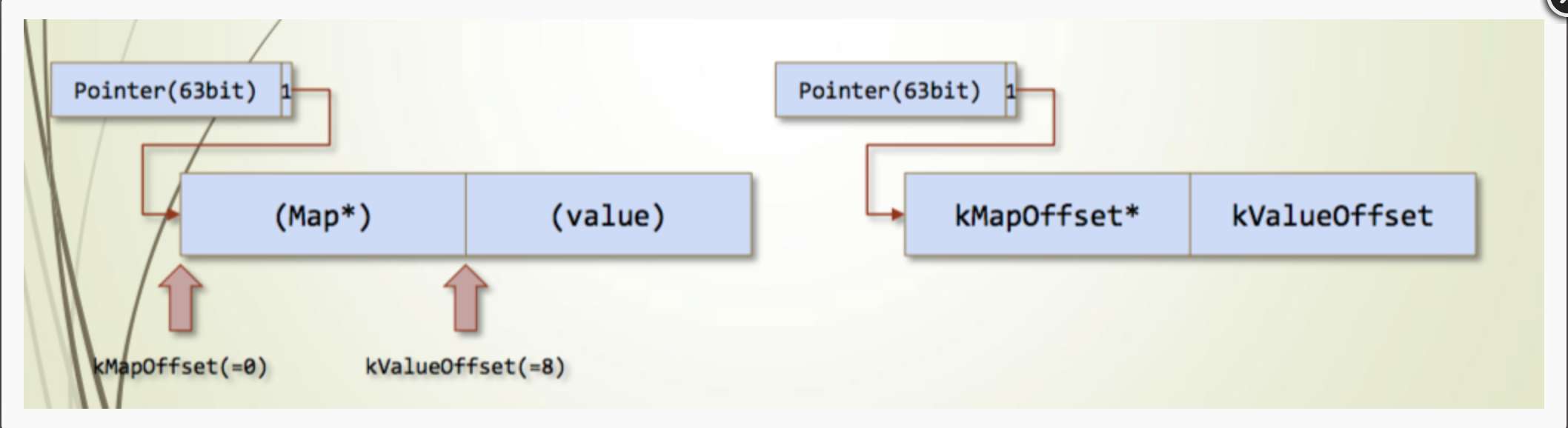
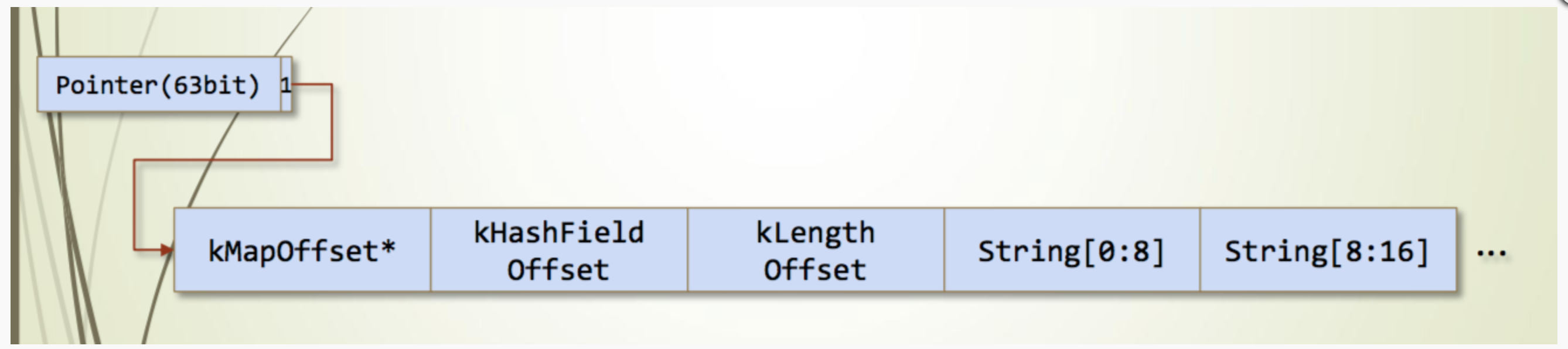
String为字符串对象
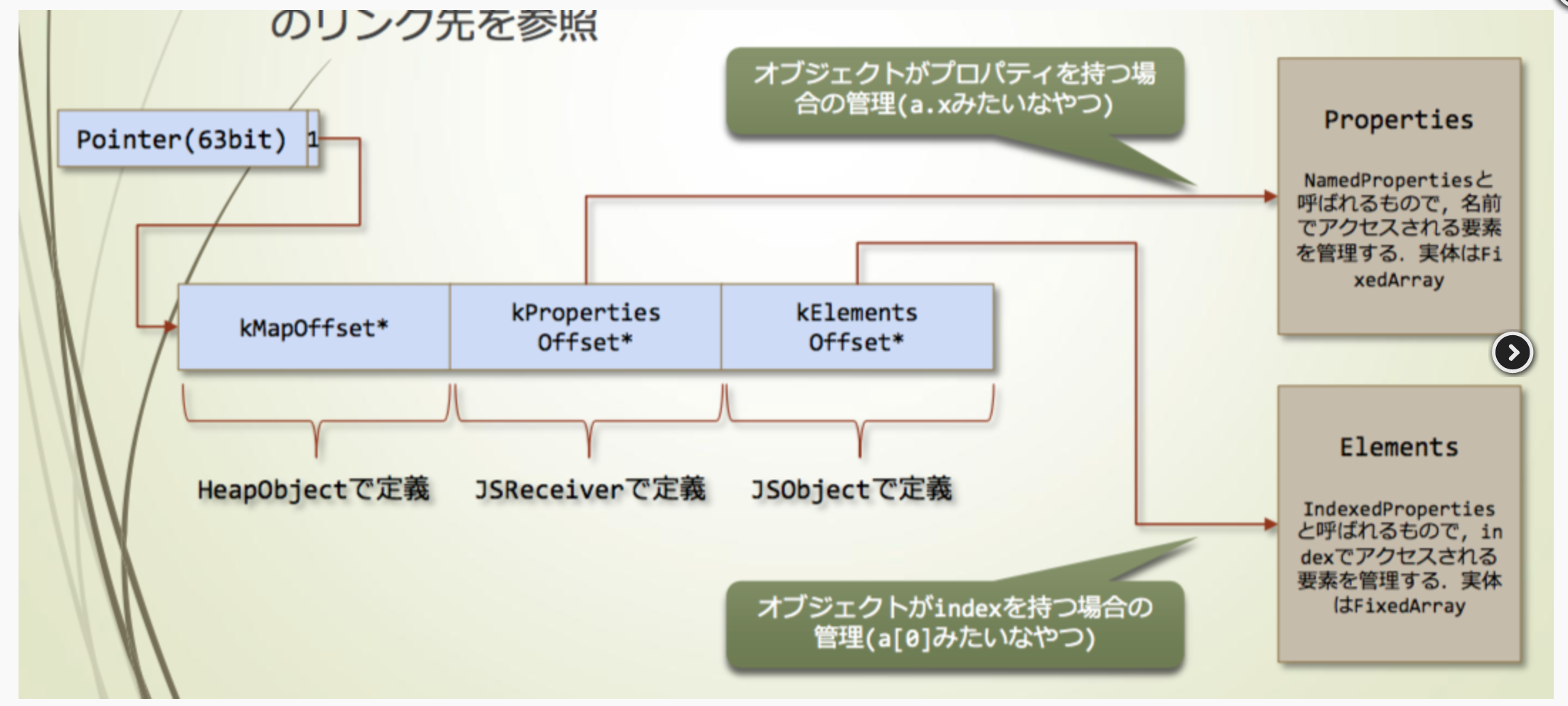
JSObject里需要关注elements和property的区别
1 | a.prop; //property |
JSFunction需要关注kCodeEntryOffset*,如果是一个JIT优化过的函数,这里指向一个rwx的区域

JSArrry
JSArraryBuffer主要是ArrayBuffer和TypedArray。前者只是一个缓冲区,后者可以绑定一个缓冲区,以不同形式进行读取。
直接创建TypedArray(这里会自己创建一个ArrayBuffer)
1 | var a = new Uint8Array(100); |
先创建ArrayBuffer在绑定TypedArray(同一个ArrayBuffer可以被多个TypedArray绑定),这也是exp编写里数据转换的方式。
1 | var a = new ArrayBuffer(8); |
GC
GC的管理可以分成两部分,young generation是针对运行时间不长,第一次gc的obj;old generation针对经过了多次gc的obj,内存回收的次数比较少;other里是针对large object的回收

GC使用cheney算法进行回收,将内存区域分成两部分,To-Space是使用的空间,From-Space是空闲的空间,obj会从前者转移到后者,living obj会拿回到to-space或者old generation(多次gc的),其余会被回收。
写内存分配相关的exp时,需要有意识地调用gc来使目标对象放在old generation里,这样布局相对稳定。
具体还可以参看a-tour-of-v8-garbage-collection
CTF题目
*CTF 2019 OOB
之前入门的调的题,OOB
数字经济云安全大赛 Browser
暑期实习面试前调的题目2019-数字经济大赛决赛-Browser
roll_a_d8
题目描述如下,我们去issue列表里搜索OOB,找到issue-821137,查看邮件中修复的部分,找到修复的commit,选择a的src查看包含漏洞的branch为1dab065bb4025bdd663ba12e2e976c34c3fa6599,这应该就是我们需要切换的漏洞版本了。
1 | 编译命令 |

漏洞分析
我们找到目标函数(由于本地src是最新源码,因此我们还是看上面那个branch的函数),这个方法是class ArrayPopulatorAssembler : public CodeStubAssembler的方法,有篇文章csa-builtins介绍了如何自己编写一个builtin。我们简单概括一下编写思路。
首先v8可以通过不同的方式实现builtin:asm/c++/js/CodeStubAssembler。
CSA提供Low-level的asm的抽象,也提供了high-level的函数的扩展
1 | // Low-level: |
CSA的builtins在TurboFan的编译阶段使用得到最终的执行代码(优化阶段不使用)
写一个CSA builtin:我们编写一个Builtin,只接受一个参数,返回值是否为42.这个builtin将install到Math以暴露给js使用,在这个例子中我们的编写步骤如下:
- 使用js linkage创建一个CSA builtin,可以像js函数一样调用它
- 使用CSA实现简单的逻辑:对Smi和Heap-number处理,条件语句,调用TFS builtins
- 使用CSA builtin
- 安装到Math这个obj上
声明MathIs42:builtins在src/builtins/builtins-definitions.h的BUILTIN_LIST_BASE宏进行声明,我们可以使用下面的代码声明CSA的builtin(带一个参数x)
1 |
|
BUILTIN_LIST_BASE使用不同的宏表示不同的builtins.CSA的builtins主要可以分为下面的:
- TFJ:JS linkage
- TFS:Stub linkage
- TFC:要求一个用户接口描述符的Stub linkage
- TFH:用于Inline Caching的特殊的stub linkage
定义写在src/builtins/builtins-*-gen.cc文件中,因为我们是在Math obj里添加builtin,所以我们在src/builtins/builtins-math-gen.cc添加如下代码.注释很详细,context是一个全局变量作用域,相当于一个window object(类比我们浏览器中打开的一个窗口),它保存了js运行的环境,下面Label类似汇编中的标签,Branch表示分支判断,为真则去label1,否则跳转到label2,每个label使用BIND绑定一个代码块进行处理。
1 | // TF_BUILTIN is a convenience macro that creates a new subclass of the given |
最后,我们在src/bootstrapper.cc中attach上这个方法(facktory用于生产新的对象)。之后我们使用Math.is42(42);调用该方法测试即可
1 | // Existing code to set up Math, included here for clarity. |
关于isolate和context可以看下Design of V8 bindings
我们回来继续看这个方法.(ps:在这里可以看到可视化更好的diff)
1 | void GenerateSetLength(TNode<Context> context, TNode<Object> array, |
我們checkout到漏洞版本后分析一下漏洞函數,全局搜索之後發現在ArrayFrom/ArrayOf有这个builtin的调用,poc中用的是from,因此我们看下from的builtin代码.同时看下js里Array.from()函数的用法。
Array.from()方法允许我们从array-like objects(有length属性以及可以用索引访问的elements)和iterable objects(比如Map和Set)中生成数组。
函数的参数为(array-like,mapFn[optional],thisArg[optional]),最常见的调用方式如下.第一种就是从字符串中split出数组,第二中定义了mapFn,我们可以将其应用在array的每个元素上,在这里就是让每个元素加倍。Array.from(obj, mapFn, thisArg)等价于Array.from(obj).map(mapFn, thisArg)。
1 | console.log(Array.from('foo')); |
另一种from的对象为迭代对象,可以参考Iteration_protocols和Iterators_and_Generators,我们构造一个迭代对象时使用[Symbol.iterator],比如下面的例子,我们定义range对象为迭代对象,编写自定义的迭代函数,value表示迭代器返回的值,done为true时表示迭代器迭代到了最后。
1 | let range = { |
poc如下,感觉上是在iter返回前先调用oobArray.length=0,之后调用GenerateSetLength设置oobArray的length属性=1024 * 1024 * 8,此时可以访问的范围超过了原elements的范围,造成越界。
1 | let oobArray = []; |
1 | // ES #sec-array.from |
然而进行到这里有个问题,上面代码中Array.from操作的arr对象是通过array设置的临时变量而后用args.PopAndReturn(array.value())返回的浅拷贝。正常我们是拿一个定义的obj_arr来进行obj_arr.from,不过其中的function返回了oob_arr。到这里俺翻了下姚老板的博客抄作业。学长之前也有这样的困惑,之后他看了es6的代码实现,我们可以在Function.prototype.call()这里看到call method的用法,其第一个参数为this。体现到poc里就是我们的函数.通常我们可以使用prototype.call实现自己的构造函数,比如下面的代码,我们为Food和Toy赋予了新的属性。
继续看es6的代码,因为this是函数指针,因此最后会执行到a = new c(len);。当我们new后面跟function时,得到的是function的返回值,也就是oobArray。
1 | function Product(name, price) { |
1 | // 22.1.2.1 Array.from ( items [ , mapfn [ , thisArg ] ] ) |
环境搭建
目标bin是32位的,checkout过去之后很多依赖也要装32位的,我这里就用64位的binary做了
漏洞利用
搭完环境之后先测下PoC,成功在release的d8上产生了崩溃。我们将poc里的max减成2000加快运行速度,漏洞触发前后分别下断点调试。
触发漏洞之后length变为了1999而elements还是长度为0的FixedArray
1 | //before |
elements
参考Elements kinds in V8了解v8中elements的概念.我们在js层看到的integer/float/double都属于number,而在engine层,需要做更细粒度的区分用于优化。
如下面的两种类型的elements
1 | const array = [1, 2, 3]; |
elements总是单向的转换到更为普适的类型。
1 | const array = [1, 2, 3]; |
上面看到的array都是packed arrays,在array中制造出一个hole出来使得elements降级为holey类型。
1 | const array = [1, 2, 3, 4.56, 'x']; |
下面是目前v8支持的element类型。
1 | enum ElementsKind { |
踩坑
我看了下之前OOB的题目笔记,发现elements和obj的位置天然相近,当时做题的时候还以为是固定的layout,但是在这个issue调试时发现并非如此。首先我们降低max的值加快运行速度,之后发现假使我们以下面的方式布置arr,最终的结果是elements和obj相距甚远。
1 | DebugPrint: 0x2469c92fbdb1: [JSArray] |
1 | var a = {"a":"1"}; |
联想一下之前看gc的时候说gc会使得obj移入old space,从而对象布局相对固定。那么我们先gc,再分配arr,调整max的值为50,发现此时elements和obj离得没那么远了,但是相应地,我们调整max的值,distance也会相应增大或者减小。再从gdb里看下数据,可以发现elements往后是拷贝的迭代器的值。到这里我们基本可以确定了,在Array.from进行数组拷贝时我们将迭代器的值拷贝到了elements所在的空间,因此虽然length改掉了,但是这块空间没有被回收,整个空间布局是oobArr->unrecovered space->double_arr->obj_arr。因此我们可以在分配后两个对象前先gc回收掉这块区域,从而布置arr到我们可以访问的范围。
1 | gc() |
1 | DebugPrint: 0x2f429437bdb1: [JSArray] |
修改一下gc的位置查看内存布局
1 | function gc() |
可以看到现在oobArray的obj已经在elements-736的位置,比较接近了,但是elements依然不能越界读写到自己的这个obj,因此我们再次修改gc位置,在每个对象定义前都加gc,最终可以使得elements越界读写到后面布置的double_arr和obj_arr.
1 | var oobArray = [3.1]; |
1 | DebugPrint: 0xe7cd6b8c5a9: [JSArray] in OldSpace |
越界读发现异常,我们根据报错在./../src/objects/fixed-array-inl.h:167下源码断点调试,发现index >= 0 && index < this->length()检查没过,后面跟下gdb发现这里的length是map+0x7即elements存储的length而非obj的length字段,这个字段为我们迭代器返回时设置的值。
1 | uint64_t FixedDoubleArray::get_representation(int index) { |
1 | gdb-peda$ x/20i $pc |
走到这里卡住,尝试了其他几种类型的FixedArray也不好使,看backtrace基本都是length的检查绕不过去,到这里刚好和keenan去吃饭,中间请教了一下obj->length和elements->length的关系,keenan讲说前者更为重要,而后者在FixedArray用的比较多,想以前者作为标准进行寻址最好是用JSArray。我们来看下js-array.h。可以看到array可以分成两种mode,fast mode/dictonary mode。我们想绕过elements的检查,因此尝试一下dictory mode的JSArray
1 | // The JSArray describes JavaScript Arrays |
在objects.cc中找到转换的函数ShouldConvertToSlowElements,调用函数AddDataElement猜测是向array中增加新的数据。当(index-capacity)>=1024时降级,或者fast mode占用的内存原大于dictory占用的内存时也会降级。
1 | // Maximal gap that can be introduced by adding an element beyond |
经过一番折腾调试,我发现我的问题在于报错的地方是DCHECK而不是CHECK,所谓的DCHECK就是debug版本的check,release版本中是没有的= =。。反应过来之后我决定还是拿之前的PoC试一下。调试数字经济的题目时有类似的痛苦,就是release版本用不了job,只能release和debug对照着看。我们先在release的文件夹下面创建一个debug文件夹poc.js的软链接方便同步expln -s ../x64.debug/poc.js ./poc.js,然后拿最早的越界poc尝试发现成功输出了。我想了下是不是可以直接patch掉debug里的DCHECK再编译呢(理论上应该可行,又去请教了柯南,我这个版本的v8可以通过修改args.gnsymbol_level=2启用源码调试:)),那我们再重新编译一下d8(:(这个方法还是不行))。还是老老实实对着调吧- . -
趁着编译查查args.gn是做什么滴。gn是个编译系统,参考build-gn了解编译的方法,上面列举了常见的参数,存储参数的配置文件就在args.gn。也可以在GN Reference深入了解。
addressOf原语
编写addressOf原语的思路和之前OOB题目比较类似,我们的目标是使用此原语得到对象的地址。先越界读arr_map和double_map。我们首先用obj_arr[0] = obj将目标对象保存到对象arr中,之后越界写obj_arr->map=double_arr_map将对象数组改为浮点数数组的类型,此时输出obj_arr[0]即为对象的地址。注意因为我们每次都要复用obj_arr,再将对象地址拷贝到临时变量后我们需要将map修改回去。
1 | function addressOf(obj) |
fakeObj原语
fakeObj原语和addressOf原语的思路相似,我们的目标是将某个地址对应的内存包装成一个合法的对象从而访问其属性。首先用double_arr[0] = i2f(addr+1)存放目标地址到数组的elements,之后越界写double_arr->map=obj_arr_map将浮点数数组改为对象数组类型,此时返回的double_arr[0]即为一个obj。但是这个address所在的内存需要为一个合法的obj,也就是说我们需要提前布置一些属性在其中,比如map/prototype/elements/length。
1 | function fakeObj(addr) |
##### arbRead/arbWrite
当我们有了上述两个原语,我们可以在其基础上构造任意地址读写的函数。首先我们通过addressOf得到double_arr对象的地址,据此根据偏移计算出double_arr->elements对象的地址,我们使用fakeObj原语将elements->content这块内存伪造成一个obj(需要布置合法的属性在其中)。对于这个伪造的对象fake_obj,我们可以通过修改double_arr元素来控制其属性elements为target_addr-0x10,再访问fake_obj[0]即可得到目标地址处的值。
同样地,对于arbWrite,我们只需要对fake_obj[0]赋值即可实现任意地址写。
1 | function arbRead(addr) |
exp.js
看着以前的博客,exp写的磕磕绊绊。这个版本的DataView没有SetUint64方法,这里拿kennan的功能函数直接来用。中间踩了很多坑,有些原理还没弄明白,这里记一下。
- 关于gc:学长说gc不必像下面一样多次调用,放在最后调用也一样,具体原理需要再看看gc
- 在构造arbRead/arbWrite时不要从
elements->content开始伪造Obj(和上面讲的原理有出入),这是因为在fakeObj中有对double_arr[0]的赋值,我们想伪造其为obj就必须让double_arr[0]恒为double_arr_maps,否则这个obj会在调用fakeObj后被认定为非法对象,因此我们越过这个元素在后面伪造对象。 - length字段需要伪造为
i2f(0x1000000000),高四字节才表示length,开始设置为2在gdb中显示大小为0 - calculator的shellcode是网上找的,看上去sc的语法和intel asm有些出入,要再研究一下
- 关于asm_addr的寻找:这里最开始用之前OOB那道题目的思路去找,发现到
data字段那块这个版本的结构体就没有这个属性了,在姚学长的数字经济那里寻找wasm的方法也不好使。刚好panda学长在旁边跟俺唠嗑,学长讲说通过code字段也可以找到wasm的地址,我调试了一下发现确实,有点像之前D3CTF里libroll那道题我找地址的方法,汇编中找call的位置2333.测试代码如下:
1 | var wasmCode = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]); |
我们首先找到f的地址
1 | DebugPrint: 0x2320c0ba7ff1: [Function] in OldSpace |
在偏移为18的地方得到shared_info的地址0x2320c0ba7ed1,再找到code字段,code+0x70+2处存放的就是wasm_addr的地址
1 | gdb-peda$ job 0x2320c0ba7ed1 |
- getshell的方法和之前相同,劫持
data_buf的backing_store为wasm_addr,通过DataView修改原本的wasm代码为shellcode,最后调用wasm_func即可 - 关于调试:这次调试还是release+debug一起调的,学长说可以修改DCHECK的宏总是返回true或者找到一个总开关注释掉,回头研究一下。
最终的exp如下。
1 | function gc() |

